Spiking Vision Transformer with Saccadic Atteition
Paper Info
| Field | Content |
|---|---|
| Title | Spiking Vision Transformer with Saccadic Atteition |
| Authors | Chenlin Zhou et al. |
| Venue | ICLR 2025 |
| Year | 2025 |
| Link | arxiv |
Summary
Problem Statement
Limitations of the Existing Spiking Transformer
SNN 기반 Vit인 Spiking Transformer는 Vit의 높은 에너지 사용을 SNN을 희소한 연산을 통해 완화시키려 한다. 다양한 attention 기법들과 학습 알고리즘이 도입되면서 적은 에너지만으로도 높은 성능을 이끌어낼 수 있게 되었다. 그러나 기존 모델들은 다음과 같은 문제가 있다.
- self-attention을 tocken mixer로만 취급하여 spike에 효과적인 관련성을 탐색하지 못함
- SNN의 시간적 역학을 간과함
따라서 이 둘을 고려한 스파이크 자체 attention 매커니즘을 개발이 필요하다.
Degraded Spatial Relevance
일반적인 self-attention은 dot product를 통해 \(Q\)와 \(K\) 간의 공간적 관련성을 측정한다.
\[\text{Dot-Product} (Q_i, K_i) = \sum_{j=1}^{D} Q_{ij}K_{ij},\]이때, dot product의 결과는 두 벡터의 각도와 크기를 모두 고려해서 산출된다. 그래서 벡터 간 길이의 차이가 클 경우, dot product는 공간적 관련성을 정확히 측정하지 못할 수 있다. ANN의 경우, 정규화된 입력 \(X\)에 선형 변환 \(W_Q\), \(W_K\)를 적용해 행렬 \(Q\)와 \(K\)를 도출한다. 이에 둘 사이의 분포가 거의 동일하기에 attention 점수는 공간적 관련성을 효과적으로 측정할 수 있다.
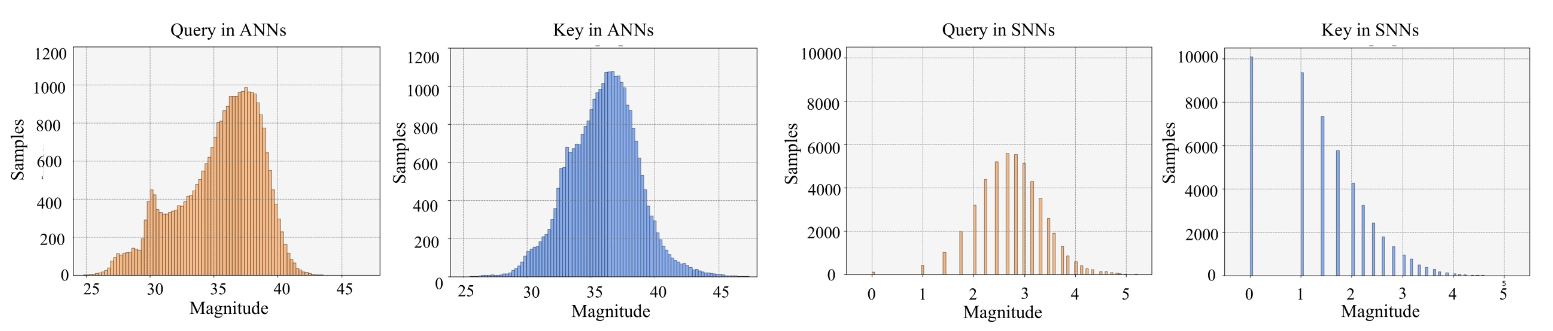
반면 SNN의 경우, 이산적인 활성화 특성으로 인해 \(Q\)와 \(K\)에서 정규화된 연속적 분포가 보장되지 않는다. 만일 동일한 분포를 따른다고 가정해도, 희소성으로 인해 안정성이 크게 감소된다. 이에 spike trains 간의 공간적 관련성을 측정하는 더 효과적인 방법을 개발하는 것이 SNN 기반 Vit의 성능을 향상시킬 수 있을 것이다.
Limited Temporal Interaction
vanilla self-attention은 time step과 독립적으로 작동하므로 attention 설계에서 시간적 상호작용을 고려하지 않아도 된다. SNN의 경우는 표현 능력을 풍부하게 하기 위해서 여러 time step에 의존한다. 그러나 기존의 Spiking Self Attention의 경우 이를 고려한 전용 모듈이 부족하다. 시간적 상호작용은 Spiking neuron의 과거 정보 축적이며, 동역학은 다음과 같다.
\[\boldsymbol{U}[t+1] = \boldsymbol{H}[t] + \boldsymbol{X}[t+1],\]여기서 \(\boldsymbol{H}\)와 \(\boldsymbol{U}\)는 각각 사전 및 사후 시냅스 막 전위를 의미한다. 이 식은 곧 사후 시냅스 막 전위가 이전 time step의 막 전위와 입력 전류의 합에 의존함을 말한다.
\[S[t+1] = \Theta(U[t+1] - V_{\text{th}}),\]이때 스파이크의 발생 여부인 \(S\)는 사후 막 전위가 임계값인 \(V_{\text{th}}\)를 넘었는지에 의해 결정된다. Heaviside function인 \(\Theta(\cdot)\)에 의해 결정된다. 임계값을 넘기면 1, 넘기지 못하면 0이 되는 것이다. 이를 고려하면 다음 레이어에 입력되는 사전 시냅스 막 전위는 다음처럼 공식화할 수 있다.
\[H[t+1] = V_{\text{reset}} S[t+1] + \tau U[t+1](1 - S[t+1]).\]스파이크 \(S\)가 발생한 경우 다음 시냅스의 막 전위는 초기값인 \(V_{\text{reset}}\)이 되고, 발생하지 않은 경우에는 \(\tau U\)가 된다. 이때 \(\tau\)는 전위가 시간에 따라 감쇠하는 정도이다. LIF 모델은 재설정 및 감쇠 메커니즘으로 인해 막 전위는 장거리로 정로를 보존할 수 없다. 이를 고려한 Spatio-Temporal Self-Attention(STSA) 설계도 있지만, \(O(T^2N^2D)\)의 계산 복잡도로 인해 학습 효율이 낮다.
Key Idea
Saccadic Spiking Self-Attention Mechanism
Spatial Relevance Computation form Spike Distribution
앞서 살펴본 dot product로 인한 공간적 관련성 저하를 완화하기 위해 본 논문에서는 cross-entropy 방식을 도입한다. \(p\)를 정규화된 스파이크 발화율이라고 했을 때 \(Q\), \(K\)의 패치 \(q \in Q\)와 \(k \in K\) 간의 교차 엔트로피는 다음과 같이 주어진다.
\[\mathcal{H}(q, k) = - \left[ p_q \log p_k + (1 - p_q) \log (1 - p_k) \right],\]전자의 항은 예측이 양성일 때의 관련성을 정량화하고, 후자의 항은 예측이 음성일 경우의 관련성을 반영한다. 즉, 이 값을 관련성 측정 값으로 사용하게 되면 두 확률 분포의 크기를 무시하고 차이를 비교하는 것이 된다. 이때 예측이 음성일 경우 즉, 침묵 기간이 활성화 상태의 정보를 가릴 수도 있기에 \((1-p_q)\mathrm{log}(1-p_k)\) 항을 무시하고 \(H(q,k)\)를 다음과 같이 단순화시킬 수 있다.
\[\mathcal{H}(a, b) \approx -p_q\mathrm{log}p_k\]여기에 SNN의 transformer 블록 내 발화율이 10~20%임을 고려해 \(x=0.15\)에서 \(\mathrm{log}(x)\)의 테일러 전개를 수행하면 다음과 같다.
\[\log(x) \approx \log^{(0)}(0.15) + \dots + \frac{\log^{(n)}(0.15)}{n!} \cdot (x - 0.15)^n\]\(x\)의 크기가 0.15임을 고려할 때 \((P_Q-0.15)^2\) 및 고차항은 매우 작아서 무시할 수 있다. 즉,
\[\log(x) \approx \log^{(0)}(0.15) + \frac{\log^{(1)}(0.15)}{1!}(x - 0.15) \approx kx + b\]처럼 선형 방정식으로 나타낼 수 있고, 이는 훈련 과정에서 가중치와 편향으로 학습될 수 있으므로, 약간의 오차를 감수하더라도 계산 단순화를 위해 \(\mathrm{log}(x)\) 대신 \(x\)를 사용할 수 있다. 이를 고려하면 다음과 같은 식이 성립한다.
\[\mathrm{CroAtt} \approx -\mathcal{H}\approx -(-p_qp_k) = p_qp_k\]결과적으로 \(Q\)와 \(K\) 간의 교차 어텐션은 다음과 같이 표현할 수 있다.
\[Q' = \sum^{D} Q, \ \ K' = \sum^{D} K\] \[\text{CroAtt}(Q, K) = Q'{K'}^T, \ \ \ Q, K \in \mathbb{R}^{T \times N \times D}\]이 근사법은 약간의 오차를 유발할 수는 있지만 \(Q\)와 \(K\) 간의 공간적 관련성을 더 정확하게 평가하며, 효율적인 병렬 계산을 가능하게 한다.
Saccadic Temporal Imteraction for Attention
생물학적 saccadic 매커니즘은 모든 시각 정보를 한번에 처리하지 않고, 장면 내 주요 시각 영역에 집중하면서 정보를 처리함으로써 전체 시각 장면의 맥락에 대한 이해를 돕는다. 본 논문에선 이에 영감을 받아 각 timestep마다 중요한 패치에 집중하면서 정보를 처리하도록 설계했다.
\[Patch = \sum_{j=1}^{n} \text{CroAtt}(Q, K), \ \ \text{CroAtt}(Q, K) \in \mathbb{R}^{T \times N \times N},\]\(\text{CroAtt}(Q, K)\)는 \(Q\)와 \(K\) 내 패치 간 공간적 관련성을 나타낸다. \(\text{CroAtt}(Q, K)\)의 행을 합산함으로써 \(Patch\)는 패치의 공간적 특징을 나타내며 이는 맥락적 이해를 수행할 수 있게 한다. 이때 SNN의 비동기적 특성을 반영하기 위해 LIF 뉴런을 사용해야하지만, LIF 뉴런의 감쇠 메커니즘으로 인한 과거 정보 망각은 효율적 상호작용을 방해하게 된다. 이에 본 논문에선 훈련 및 추론 단계에서 다른 수식을 사용하는 saccadic 스파이킹 뉴런을 도입한다.
\[\begin{align*} \text{Training}\; & \begin{cases} \mathbf{H} = \mathbf{M}_w \mathcal{P}\text{atch} \\ \mathbf{S} = \Theta(\mathbf{H} - \mathbf{V}_{\text{th}}) \end{cases} \qquad \text{Inference}\, & \begin{cases} \mathbf{H}[t] = \mathcal{P}\text{atch}[t] \\ \mathbf{S}[t] = \Theta(\mathbf{H}[t] - \mathbf{M}_w^{-1}\mathbf{V}_{\text{th}}[t]) \end{cases} \end{align*}\]이때 \(\mathbf{H}\), \(\mathbf{S}\), \(\mathcal{P}\text{atch} \in \mathbb{R}^{T \times N}\)은 전체 시간 차원을 포함하는 병렬 훈련을 위한 데이터 형식이다. \(\mathbf{M}_w\)는 하삼각 행렬로, 이전 timestep이 다음 단계를 참조하지 못하게 하면서 감쇠, 혹은 reset으로 인한 정보 망각을 회피한다. training 단계에서 saccadic 스파이킹 뉴런의 막전위는 \(\sum_0^t w_{it}\mathcal{P}\text{atch}[t]\)로 표현되는데 이는 상당한 계산량을 요구한다. SNN의 에너지 효율성을 유지하기 위해 inference 단계에서는 \(\mathbf{M}_w\)의 역행렬을 임계값에 통합함으로써 \(H\)와 \(S\) 간의 시간적 분리를 보장한다. 이 경우 시간 복잡도는 \(O(T)\)에 불과하게 된다.
Linear Complexity and Spike-Driven Computation
위에서 언급한 구성요소를 모두 포괄한 SSSA는 다음과 같이 표현할 수 있다.
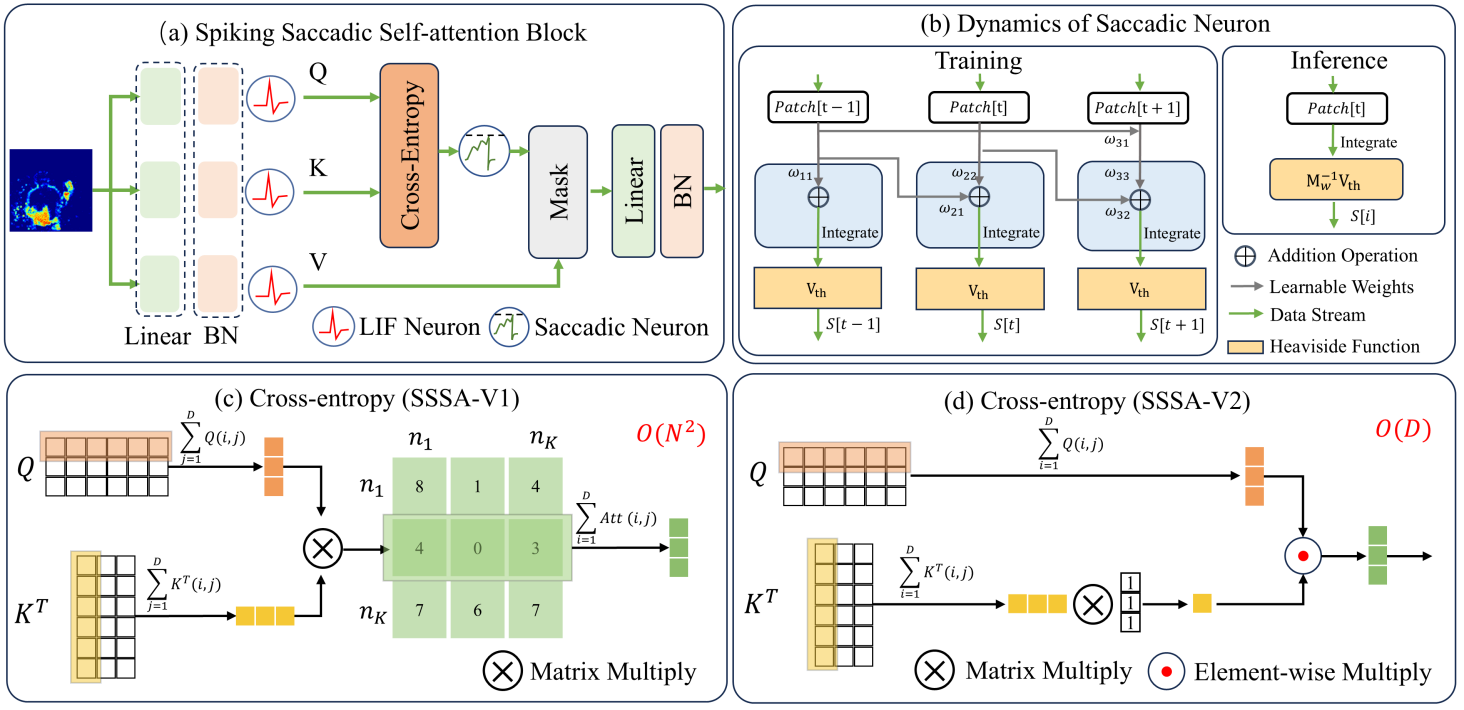
여기서 \(L\)은 차원 \(N\)을 갖는 열 벡터 [1, 1, …, 1]이며, 행 합산을 위한 값이다. 이 경우 \(\mathcal{Q}' \times \mathcal{K}'\) 내에 정수 곱셈 연산이 포함되어 있어 SNN의 에너지 효율성을 저해한다. 또한 \(\mathcal{Q}' \times \mathcal{K}'\)는 이차 복잡도를 가지고 있다는 단점이 있다. 위 식의 행렬 곱셈은 비선형 연산을 포함하지 않으므로 선형 스케일링 매핑을 수행해 다음과 같이 식을 바꿀 수 있다.
\[\mathrm{SSSA}(\mathcal{Q}, \mathcal{K}, \mathcal{V}) = \Theta\left(\left(M_w \times \mathcal{Q}'\right)\left(\mathcal{K}'^T \times L\right) - V_{th}\right) \cdot \mathcal{V}\]이 경우 즉, SSSA-V2에서 \(\mathcal{Q}'\)와 \(\mathcal{K}'\) 각각의 계산 복잡도는 \(O(D)\)이다. 그 뒤에 \(\mathcal{Q}'\times\mathcal{K}'\)를 계산하는 대신 \((\mathcal{K}'^T\times L)\)을 학습 가능한 스케일링 인수 \(\alpha\)로 취급하여 saccadic 뉴런의 임계값인 \(V_{th}\)에 적용한다. 이어서 \(M_w\times \mathcal{Q}'\)를 패치로 취급해 saccadic 뉴런에 입력한다. 추론 과정에서 완전한 스파이크 기반 시스템을 유지하기 위해 \(M_w\)를 saccadic 뉴런의 임계값에 통합할 수 있다.
\[\text{Inference} \begin{cases} H_{[t]} = \mathcal{Q}'[t], \\ S_{[t]} = \Theta \left(\mathbf{H}[t] - \frac{1}{\alpha} \left(\mathbf{M}^{-1}_w \mathbf{V}_{th}\right)[t]\right) \end{cases}\]수학적으로 봤을 때, SSSA-V2는 SSSA에 대한 선형 스케일링 매핑으로, SSSA의 모든 장점을 유지하면서도 정수 곱셈의 필요성을 줄인다. 결과적으로 총 계산 복잡도가 \(O(2D+N)\)이 되어 리소스가 제한된 환경에서 이점을 제공한다.
Methods
Results
Discussion
Insights
References
-