Surrogate Gradient Learning in Spiking Neural Networks
Paper Info
| Field | Content |
|---|---|
| Title | Surrogate Gradient Learning in Spiking Neural Networks |
| Authors | Emre Neftci, Hesham Mostafa, Friedemann Zenke |
| Venue | IEEE Signal Processing Magazine |
| Year | 2019 |
| Link | arxiv |
One-line Summary
Spiking Neural Network의 미분불가능성으로 인한 학습의 한계를 Surrogate Gradient Learning을 사용해서 극복했다.
Problem Statement
Challenges in Training SNNs
- RNN과의 유사성: temporal dependencies로 인한 최적화 문제 발생
- binary한 출력: 미분이 불가능해 안정적 학습이 불가능
- 얕은 층에서의 학습은 성공했지만, 은닉층이 있는 SNN 학습은 여전히 힘듦
SNN in Neuromorphic Hardware
- network model의 활용이 embedded 기기까지 확장되면서 전력효율의 중요성이 부상
- neuromorphic hardware는 저전력이지만 binary한 neuron을 emulate함 즉, 기존의 network model을 사용하는 데에 한계가 있음
- SNN은 neuromorphic에 특화되었으며, SNN의 층을 깊게 만드는 것(성능을 올리는 것)은 저전력 에플리케이션에 유리
Objective of the Paper
- hidden layer를 가진 SNN 훈련의 어려움을 논의하고, 이를 해결하기 위한 다양한 전략을 소개하려 함
Key Idea
Understanding SNNs as RNNs
Biological neuron
SNN이 생물학적 뉴런에서 유래된만큼 그에 대해 이해하는 것이 필수적이다.
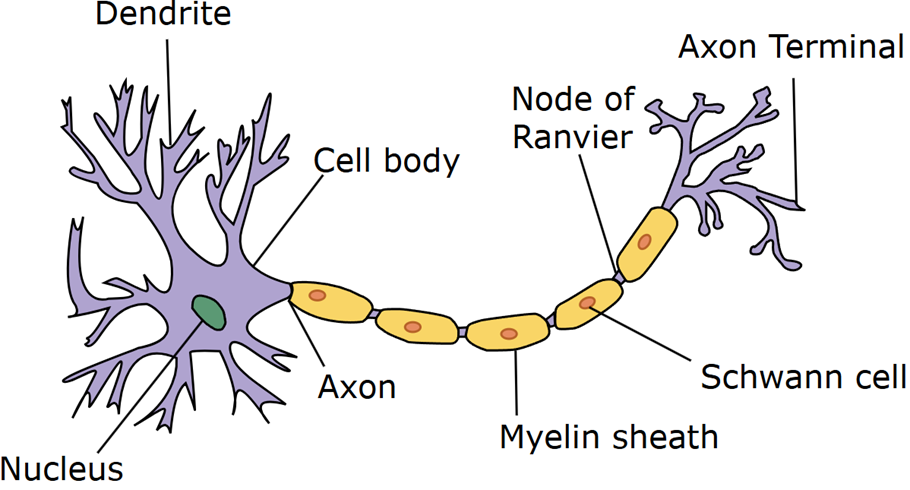
여기서 중요하게 볼 부분은 다음과 같다.
- cell body: neuron의 몸체 부분이며, 여기에 모인 전류가 일정 수준을 넘어서면 spike를 발생시킨다.
- dendrite: neuron의 입력 기관이며 여러 neuron에서 발생한 spike를 synapse를 통해 받아들인다.
- axon: neuron의 출력 기관이며, spike 발생 시 synapse를 통해 다른 neuron에 신호를 전달한다.
즉 neuron은 다른 여러 neuron의 신호를 합산해 특정 임계값(threshold)을 넘어가면 spike를 방출하는 역할을 한다.
LIF(Leaky Integrate-and-Fire) neuron model
LIF는 생물학적 neuron에서 발생하는 temporal dynamic을 RC Circuit(Resistor-Capacitor Circuit)으로 모델링하여 미분방정식으로 나타낸 것이다.
먼저 막 전위는 다음과 같이 나타낸다.
\[\tau_{mem}{dU_i^{(l)}\over dt} = -(U_i^{(l)}-U_{rest})+RI_i^{(l)}\]여기서 $U_{i}^{(l)}$는 막 전위, $U_{rest}$는 휴지전위, $I_i^{(l)}$은 입력 전압, R은 저항이다. 이 미분방정식은 입력 전압의 크기와 유무에 따라 막 전위가 어떻게 변하는지를 모델링한다. 입력이 없으면 막 전위는 휴지전위로 돌아가려고 한다.
입력 즉 시냅스 전류는 다음 미분방정식을 통해 나타낼 수 있다.
\[\frac{dI_i^{(l)}}{dt} = \underbrace{-\frac{I_i^{(l)}(t)}{\tau_{\text{syn}}}}_{\text{exp. decay}} + \underbrace{\sum_j W_{ij}^{(l)} S_j^{(l-1)}(t)}_{\text{feed-forward}} + \underbrace{\sum_j V_{ij}^{(l)} S_j^{(l)}(t)}_{\text{recurrent}}\]각 부분에 대해 설명하자면,
- exp.decay: 시냅스 전류의 지수적 감쇠(exponential decay)를 나타내며, 입력이 없으면 시간이 지남에 따라 자연스레 0에 수렴하게 된다.
- feed-forward: 이전 layer의 뉴런에서 전달된 값의 총합. $W_{ij}^{(l)}$는 뉴런 사이의 연결 강도를 나타내며, $S_j^{(l-1)}(t)$는 이전 뉴런이 발생시킨 spike를 의미한다.
- recurrent: 현재 layer의 뉴런에서 전달된 값의 총합. $V_{ij}^{(l)}$는 뉴런 사이의 연결 강도를 나타내며, 각 계층 내의 명시적인 순환(recurrent)연결에 해당한다.
이 세 부분의 합이 input을 결정하게 된다. 여기에 막 전위를 $(\vartheta-U_{reset})$만큼 순간적으로 감소시키는 항을 추가하면 처음 식을 통합할 수 있다.
\[\frac{dU_i^{(l)}}{dt} = -\frac{1}{\tau_{\text{mem}}} \left( U_i^{(l)} - U_{\text{rest}} + RI_i^{(l)} \right) + S_i^{(l)}(t) \left( U_{\text{rest}} - \vartheta \right)\]식을 보면 입력이 없을땐 $U_{rest}$로 점점 가까워지다가, 입력이 일정 수준$(\vartheta)$을 넘어서는 순간 $(U_{rest})$로 감소하는 것을 알 수 있다.
위 두 선형 미분 방정식을 통해 LIF를 따르는 단일 뉴런을 시뮬레이션할 수 있는데, 그래프를 사용해서 시각화하면 다음과 같이 표현할 수 있다.
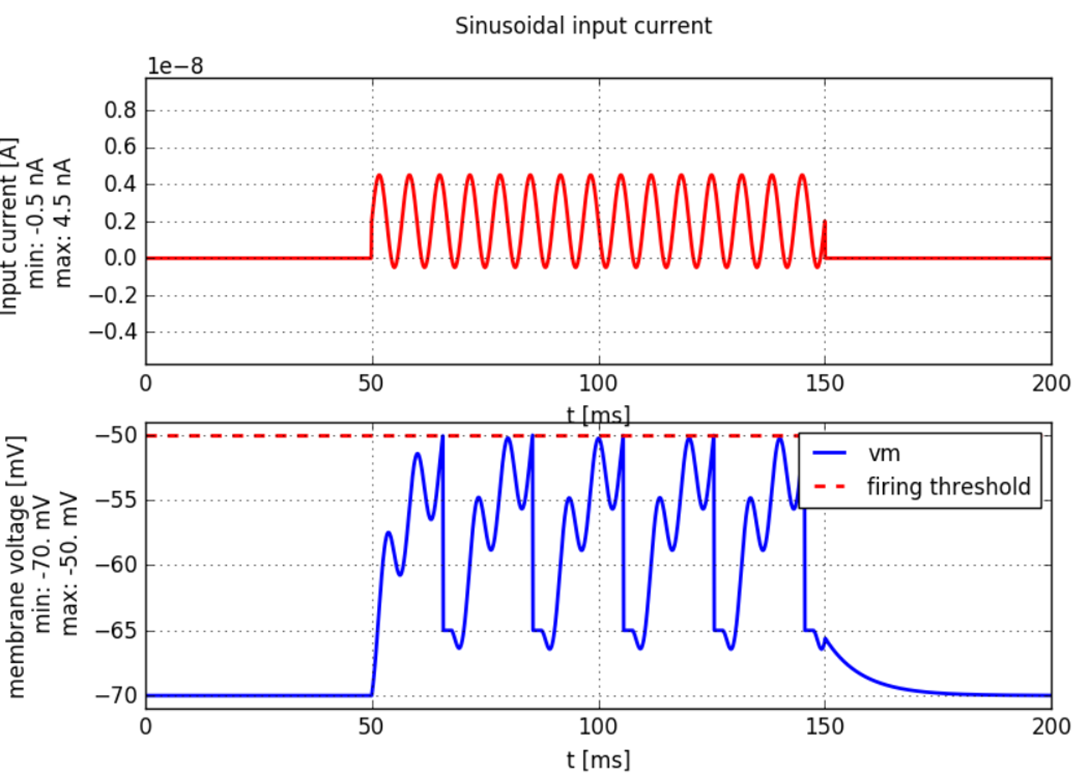
LIF(Leaky Integrate-and-Fire) in discrete time
실제 계산에 활용하기 위해 LIF 모델을 다음과 같이 이산시간에 수치적으로 근사할 수 있다.
\[I_i^{(l)}[n + 1] = \alpha I_i^{(l)}[n] + \sum_j W_{ij}^{(l)} S_j^{(l)}[n] + \sum_j V_{ij}^{(l)} S_j^{(l)}[n]\] \[U_i^{(l)}[n + 1] = \beta U_i^{(l)}[n] + I_i^{(l)}[n] - S_i^{(l)}[n]\]여기서 출력 스파이크 열인 $S_i^{(l)}[n]$은 비선형 함수로 표현 가능하다.
\[S_i^{(l)}[n] \equiv \Theta(U_i^{(l)}[n] - \vartheta)\]식을 잘 보면 RNN의 동역학을 특징짓는 것을 알 수 있다. 식을 그림으로 표현해서 보면 이해가 쉬운데, 다음은 위의 식을 시간축으로 펼친 그림이다.
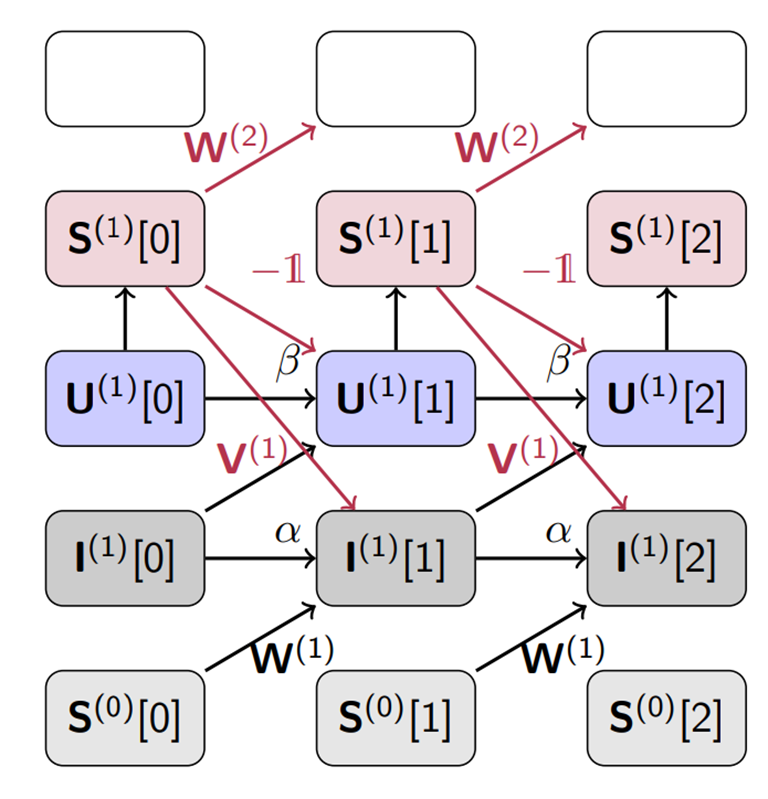
보면 우리가 알고 있는 RNN을 시간축으로 펼친 모습과 유사하 것을 알 수 있다. 이는 LIF 모델에 기반한 SNN을 마치 RNN처럼 다룰 수 있음을 함축한다.
Methods for Training RNNs
Spatial credit assignment
신용 할당(credit assignment)은 오차에 대해 어느 뉴런이 얼마만큼 책임이 있는가를 결정하는 문제이다. 오류역전파 알고리즘을 사용하면 이 문제를 쉽게 해결할 수 있다. 그러나, (1) 기울기가 네트워크를 통해 역방향으로 통신되어야 한다는 점과 (2) 오차가 사용 가능해질 때까지 뉴런 상태를 메모리에 유지해야한다는 단점이 있다.
Temporal credit assigment
RNN의 훈련에는 네트워크의 시간적 상호 의존성도 고려해야 한다. 일반적으로 이를 해결하기 위한 방법으로 두 가지가 제안된다.
-
The “Back” method
이 방법은 RNN을 시간축으로 unrolling하여 역전파 알고리즘을 그대로 적용한다. 역전파 알고리즘에서의 한계를 그대로 갖고온다.
-
The “Forward” mothod
forward 방식은 gradient 계산에 필요한 정보를 순방향으로 전파한다.
\[\Delta W^m_{ij} \propto \frac{\partial \mathcal{L}[n]}{\partial W^m_{ij}} = \sum_k \frac{\partial \mathcal{L}[n]}{\partial y^{(L)}_k[n]} P^{L,m}_{ijk}[n], \text{ with } P^{(l,m)}_{ijk}[n] = \frac{\partial}{\partial W^m_{ij}} y^{(l)}_k[n]\]이 식에서 $\Delta W^m_{ij}$는 가중치의 변화량을 의미하며 이는 전체 손실에 각 가중치가 기여한 정도에 비례하게 된다. 손실에 대한 가중치의 영향은 출력이 손실에 준 영향 $\left(\frac{\partial \mathcal{L}[n]}{\partial y_k^{(L)}[n]} \right)$과 가중치가 출력에 준 영향$\left(P_{ijk}^{L,m}[n]\right)$의 곱으로 표현할 수 있다.
가중치가 출력에 준 영향인 $P^{L,m}_{ijk}[n]$는 다음과 같이 표현 가능하다. \(P^{(l,m)}_{ijk}[n] = \sigma'(a^{(l)}_k[n]) \left( \sum_{j'} V^{(l)}_{ij'} P^{(l,m)}_{ijj'}[n-1] + \sum_{j'} W^{(l)}_{ij'} P^{(l-1,m)}_{ijj'}[n-1] + \delta_{lm} y^{(l-1)}_i[n-1] \right)\)
여기서 각 항은 다음을 의미한다.
- $\sum_{j’} V_{ij’}^{(l)} P_{ijj’}^{(l,m)}[n-1]$: 이전 시간 단계에서의 recurrent weight를 통한 영향력
- $\sum_{j’} W_{ij’}^{(l)} P_{ijj’}^{(l-1,m)}[n-1]$: 이전 레이어와 이전 시간 단계에서 전달된 feed-forward 영향력
- $\delta_{lm} y_{i}^{(l-1)}[n-1]$: kronecker delta로, $m=l$일때만 이전 레이어의 출력이 더해짐
BPTT의 공간 복잡도는 $O(N)$인 반면, 순방향의 경우 변수 $P^{(l,m)}_{ijk}[n]$를 유지해야 하므로 $O(N^3)$의 공간 복잡도를 가진다. 그러나 뒤에서 살펴볼 단순화 방법을 통해 공간복잡도를 $O(N)$ 수준까지 줄일 수 있으며, 생물학적 관점에서 봤을 때 뇌의 시냅스 가소성 및 삼중요인(뒤에서 논의)의 규칙과 일치시킬 수 있기에 BPTT 방식보다 더 매력적이다.
Methods
Overall Architecture
(figure description or simple diagram)
Key Equations
\[여기에 수식\]Algorithm Summary
1. 2. 3.
Results
- Dataset:
- Baseline:
- Key Results:
Thoughts / Questions
- What’s interesting:
- What I don’t understand yet:
- Follow-up papers to read:
References
-