Spike-Driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring The Design of Next-Generation Neuromorphic Chips
Paper Info
| Field | Content |
|---|---|
| Title | Spike-Driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring The Design of Next-Generation Neuromorphic Chips |
| Authors | Man Yao et al. |
| Venue | ICLR |
| Year | 2024 |
| Link | arxiv |
Summary
Spike-driven Trnasformer에 Meta-transformer의 구조를 응용시켜 더 발전시킨 논문
Problem Statement
SNN Transformer for Neuromorphic Chip
SNN은 뉴로모픽 칩에서 가동했을 때 sparse ACcumulates(AC) 연산을 통해 전력 소모를 줄일 수 있다는 이점이 있다. 기존 일반적인 뉴로모픽 칩은 스파이크 구동 Conv 및 MLP 연산자를 지원하고 있다. SNN 분야에도 Transformer를 적용한 Spikformer 방식이 등장했지만 대부분의 경우 에너지 소모가 많은 Multiply-and-ACcumulate(MAC)연산 때문에 SNN의 저전력 이점을 활용하기 못하고 뉴로모픽 칩에 적용하기도 힘들다.
최근에서야 Spike-driven self attention을 개발하면서 스파이크 구동 방식을 Transformer에 적용했지만 기존 Conv 기반 SNN에 비해 명확한 이점을 보여줬다고 보기 힘들다. 이에 본 연구에서는 network structure(MetaFormer), fully AC operation, skip-connection을 포함하는 Transformer 기반 SNN의 메타 아키텍쳐를 조사해보려 한다.
Key Idea
MetaFormer in ANN
MetaFormer란 Weihao Yu et al.이 처음 주장한 개념으로, Transformer의 attention layer를 “Tocken Mixer”라는 개념으로 재정의한다. 여기에 따르면 Tocken을 교환하는 연산을 한다면 굳이 attention이 아니더라도 충분한 성능을 낼 수 있다. 결국 transformer의 성능은 attention 매커니즘이 아니라, “Tocken Mixer + Channel Mixer”라는 구조에서 온다고 볼 수 있다.
구체적으로 보면 다음 수식과 같다. 먼저 입력은 특정 토큰으로 embedding된다.
이후 tocken sequence는 반복되는 MetaFormer 블록에 공급된다. 한 개의 블록은 다음과 같은 구조를 가진다.
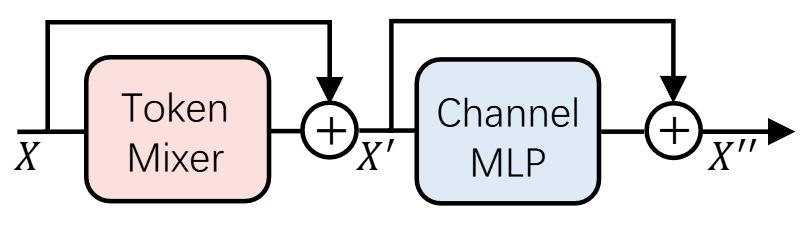
-
Tocken Mixing
\[X' = \mathrm{TockenMixer}(\mathrm{Norm}(X)) + X\] -
Channel Mixing
\[X'' = \sigma(\mathrm{Norm}(X')W_1)W_2+X'\]
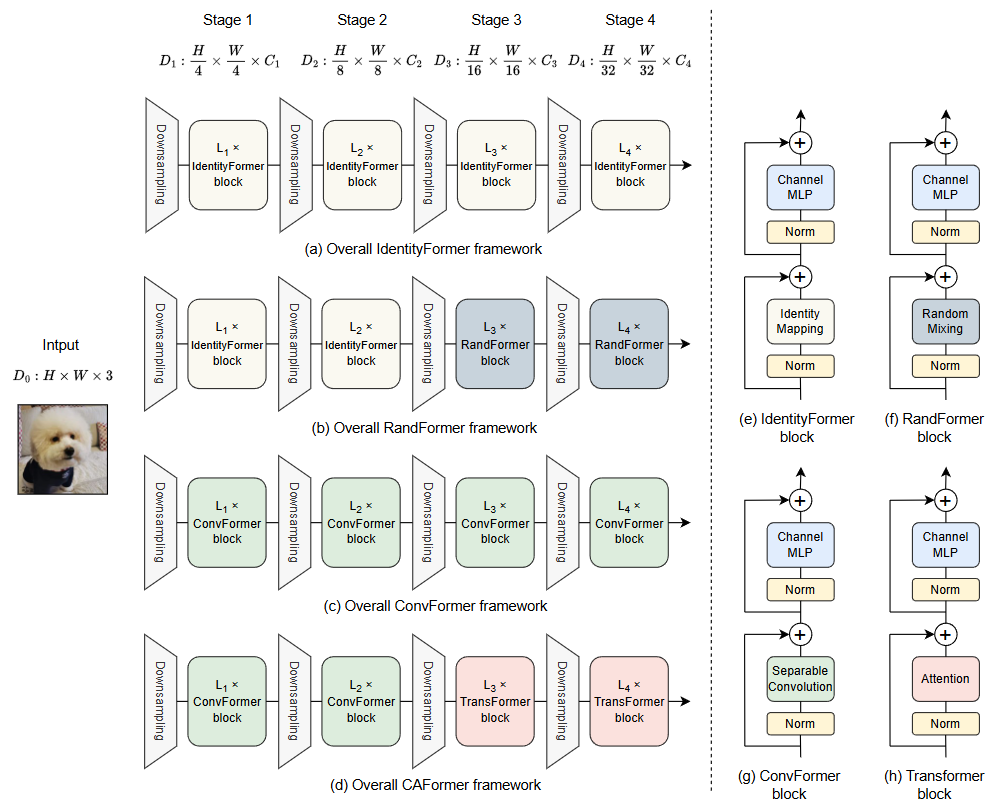
MetaFormer를 처음 제안한 논문에서는 다음처럼 여러 구조를 시도해보았으며, 이 중 Overall CAFormer framework가 가장 좋은 성능이 나왔다. 본 논문에서도 이 구조를 전체 구조로 채택한다.
Spike-Driven Self Attention (SDSA)
Vanilla Self-Attention (VSA)
기존 Self-Attention은 주어진 실수 입력 $X\in\mathbb{R}^{N\times D}$에 대해 선형 행렬 연산을 통해 $Q$, $K$, $V$를 계산하며, 이때 $N$은 토큰 수, $D$는 채널 차원이다. 일반적인 scaled dot product self attention은 다음과 같이 계산된다.
\[\mathrm{VAS}(Q, K, V)=\mathrm{softmax}\left({QK^T\over\sqrt{d}}\right)V\]수식에서 볼 수 있듯이 VSA는 Query와 Key를 dot product를 통해 계산하고 softmax를 통과시켜 확률값으로 변환시킨 뒤 Value와의 행렬곱 연산을 통해 최종적인 값을 도출한다. 그 결과 계산 복잡도는 $O(N^2D)$가 되며 이는 토큰 수 $N$의 제곱에 비례해서 증가한다.
Spike-Driven Self Attention (SDSA)
SDSA는 SNN을 기반으로 작동하기에 입력 sequence는 $S\in\mathbb{R}^{T\times N\times D}$의 형태가 된다. 이때 $Q_S, K_S, V_S\in\mathbb{R}^{T\times N\times D}$는 3$\times$3 커널 크기를 갖는 re-parameterization convolution(Ding et al. 2021)을 통해 계산된다.
re-parameterization convolution
re-parameterization은 훈련 때와 추론 때 모델의 구조, 연산방식은 바뀌지만 결과값은 바뀌지 않도록 파라미터를 다시 계산하는 것을 말한다. 논문에서 쓰인 re-parameterization convolution은 훈련 시에는 3$\times$3 Conv, 1$\times$1 Conv, Identity를 병렬로 사용하다가 추론 시에는 하나의 3$\times$3 Conv로 합치는데, 이 방식을 사용하면 학습 성능은 높으면서도 추론 속도는 빠른 모델을 얻을 수 있다.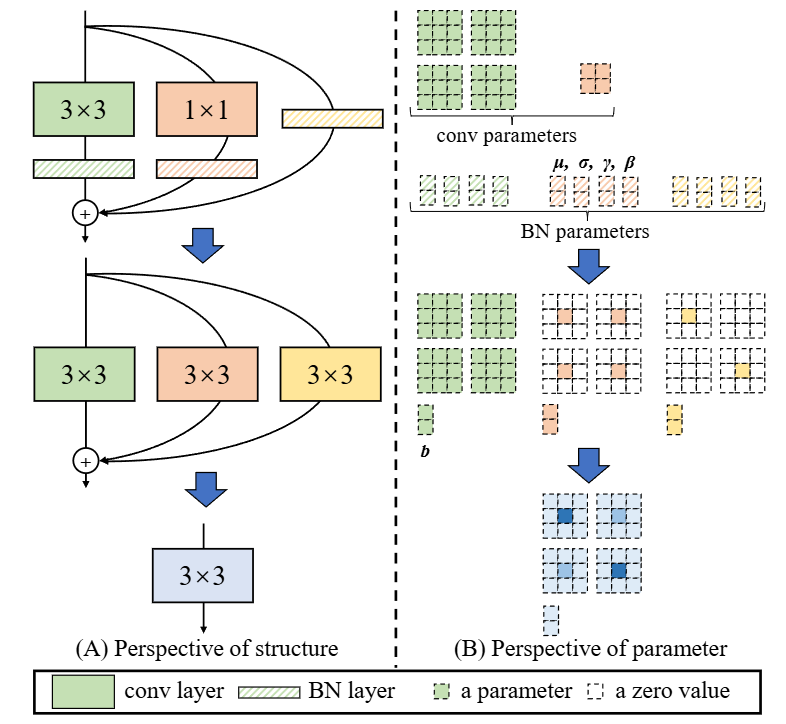
이렇게 계산된 Query, Key, Value는 SDSA 버전에 따라 다르게 계산된다.
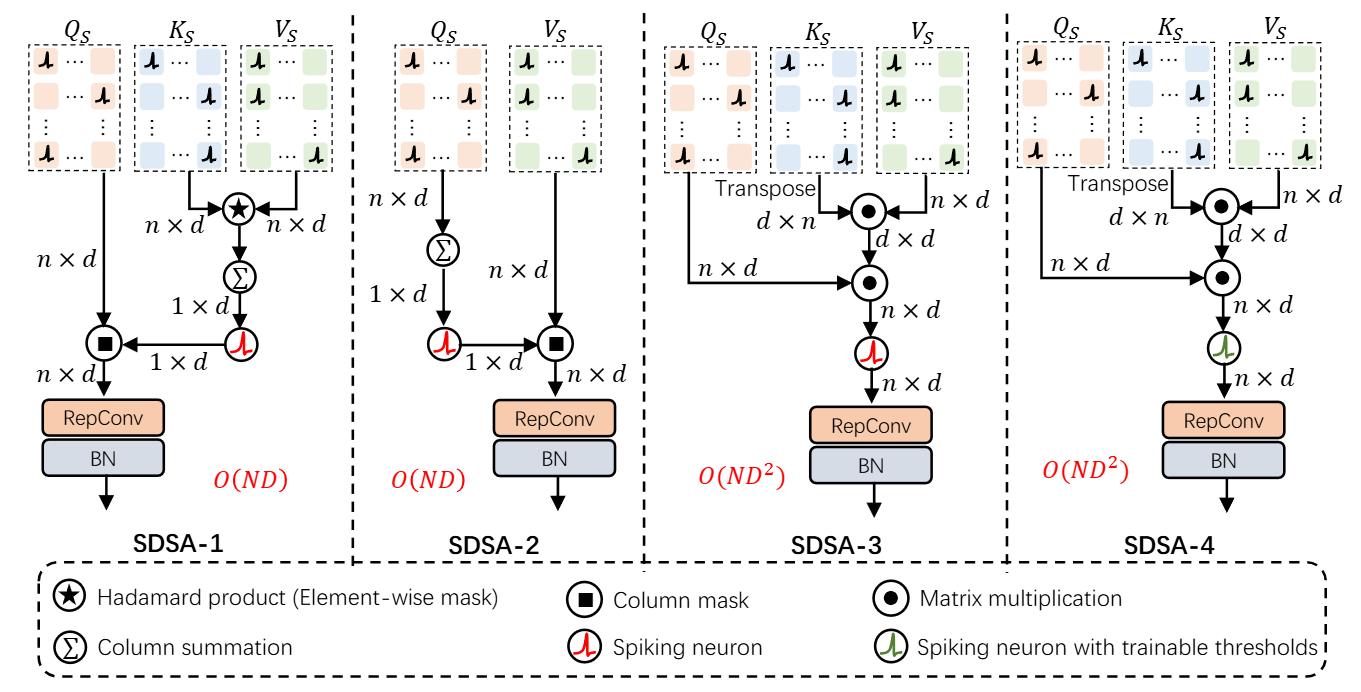
1. SDSA-1
SDSA-1은 행렬 곱셈을 요소별 곱(hadamard product)으로 대체한다.
\[\mathrm{SDSA}_1(Q_S, K_S, V_S) = Q_S \otimes \mathrm{SN}(\mathrm{SUM}_c(K_S \otimes V_S))\] 여기서 $\mathrm{SUM}_c(\cdot)$과 $\mathrm{SN}(\cdot)$은 softmax와 scale의 역할을 대신한다.
SDSA-1의 계산 복잡도 산출에 앞서 linear attention에 대해 알아보자. linear attention은 VSA에서 softmax를 제거한 것으로, 이 경우 $K_S^TV_S$를 먼저 계산할 수 있다. 이때 계산 복잡도는 $O(ND^2)$이 되어 N에 대해 선형적인 관계가 된다.
SDSA-1 역시 softmax연산이 없기에 $K_S$와 $V_S$를 먼저 계산할 수 있다. $K_S \otimes V_S$ 연산은 $K_S$, $V_S$에서 공통적으로 활성화된 특징을 추출하게 되며, 계산 복잡도는 $O(ND)$가 된다. 이후 열 방향으로 모으고 spiking neuron layer를 지나게 함으로써 특징 벡터를 추출한다. 그리고 이를 $Q_S$에 broadcast하여 중요한 특징을 산출해낸다.
2. SDSA-2
SDSA-2는 $K_S$를 사용하지 않고 $Q_S$에서 특징벡터를 바로 추출한 뒤 $K_S$에 broadcast한다.
\[\operatorname{SDSA}_2(Q_S, V_S) = \operatorname{SN}(\operatorname{SUM}_c(Q_S)) \otimes V_S\]이 경우 SDSA-1과 거의 비슷한 정확도를 보이면서도 파라미터의 개수와 전력 소모량을 줄일 수 있다는 장점이 있다. 계산 복잡도는 여전히 $O(ND)$를 가진다.
3. SDSA-3
SDSA-3은 이 논문에서 기본적으로 사용되는 방식으로,
\[\mathrm{SDSA}_3(Q_S, K_S, V_S) = \mathrm{SN}_s(Q_S(K_S^T V_S)) = \mathrm{SN}_s((Q_S K_S^T)V_S)\]앞서 linear attention의 경우에서 봤듯, $Q_S(K_S^T V_S)$ 순서로 계산했을 때 계산 복잡도는 $O(ND^2)$이 되어 $N$에 대해 선형적인 시간이 걸린다. $Q_SK_S^T V_S$ 연산은 큰 정수를 생성하므로 gradient vanishing을 피하기 위해선 scaling이 필요한데, SDSA-3는 이를 spiking neuron의 임계값에 $s$를 통합해 $s$를 곱하는 것으로 우회한다. 이에 $SN(\cdot)$의 임계값은 $s\cdot u_{th}$가 되며, $\mathrm{SN}_s(\cdot)$으로 표기한다.
4. SDSA-4
SDSA-4는 SDSA-3의 임계값을 학습 가능한 파라미터로 설정한 것이며, 초기화 값은 $s\cdot u_{th}$이다. SDSA-3과 성능이 거의 동일하며, firing rate가 약간 작기에 에너지 효율성이 조금 높다.
Shortcut
SNN의 잔차 학습에서는 크게 두 가지 측면을 고려해야 한다.
- Identity mapping의 실현 즉, 입력 x를 반영 가능한가의 문제
- 저전력 기반인 spike-driven computing을 보장할 수 있는가? SNN에서는 3 종류의 shortcut이 있는데 위의 기준을 고려해가면서 살펴보자.
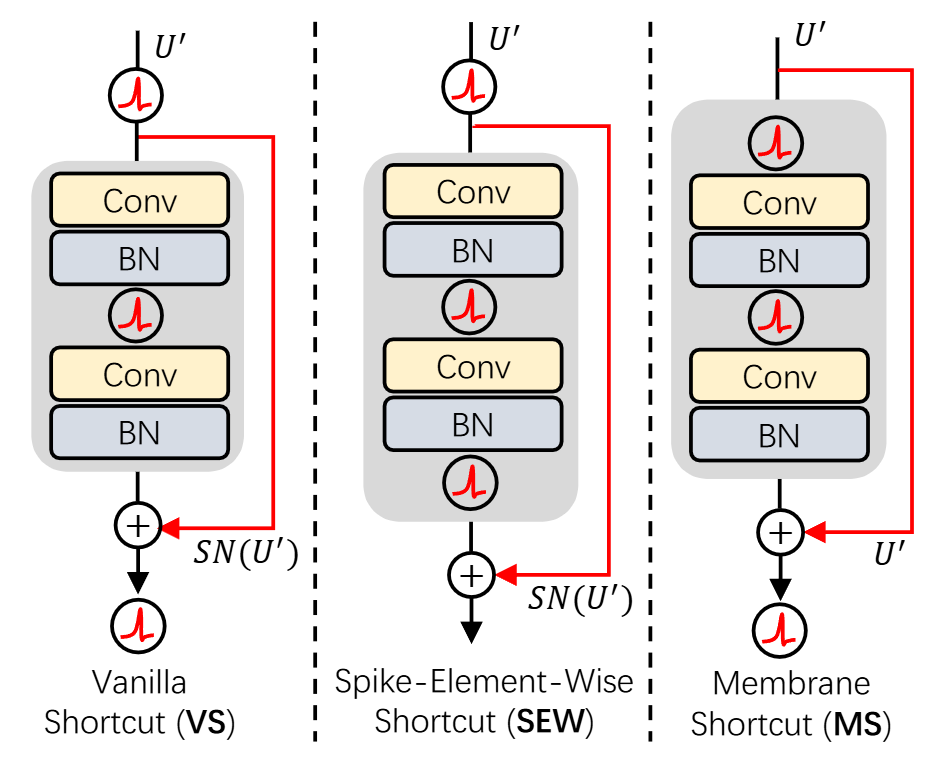
1. Vanila Shortcut(VS)
VS의 경우, identity mapping이 보장되지 않는 치명적 문제가 있다. VS를 식으로 표현하면 $y=\mathrm{SN}(f(x)+x)$가 되는데 이때 입력인 $x$는 spiking neuron을 통과한 이진값이고, $f(x)$는 실수값이기 때문에 둘을 더한 값을 spiking neuron을 통과시키게 되면 x가 보존되지 않는다. 결국 identity mapping을 보장하지 못해 vanish gradient 문제가 발생한다.
2. Spike-Element-Wise shortcut(SEW)
SEW는 VS와는 달리 이진값끼리 더하는 연산을 수행하며, 이 값을 그대로 다음 층의 입력으로 받기에 identity mapping이 보장된다고 할 수 있다. 그러나 이진값끼리 더하는 연산은 이진값이 아닌 실수값(0, 1, 2)을 출력하게 되므로 spike-driven computing이 아니게 된다는 치명적인 문제점이 존재한다.
3. Membrane Shortcut(MS)
MS는 SEW처럼 층 사이에 spike 뉴런을 두지 않는다. 그와 동시에 블록 시작점에 Spike 뉴런을 둠으로써 블록 내부 연산은 SNN처럼 돌아가게 한다. 이 경우 블록의 출력은 실수값이 되어 이전 블록의 출력값과 더하는 방식으로 shortcut을 구현할 수 있다. 이 방식을 사용하면 identity mapping과 spike-driven computing을 모두 보장할 수 있다. 이에 본 논문에선 MS 방식을 채택하였다.
Methods
Overall Architecture
Meta-Transformer와 SDSA를 적용한 Meta-spikformer의 전체적인 구조는 다음과 같다.
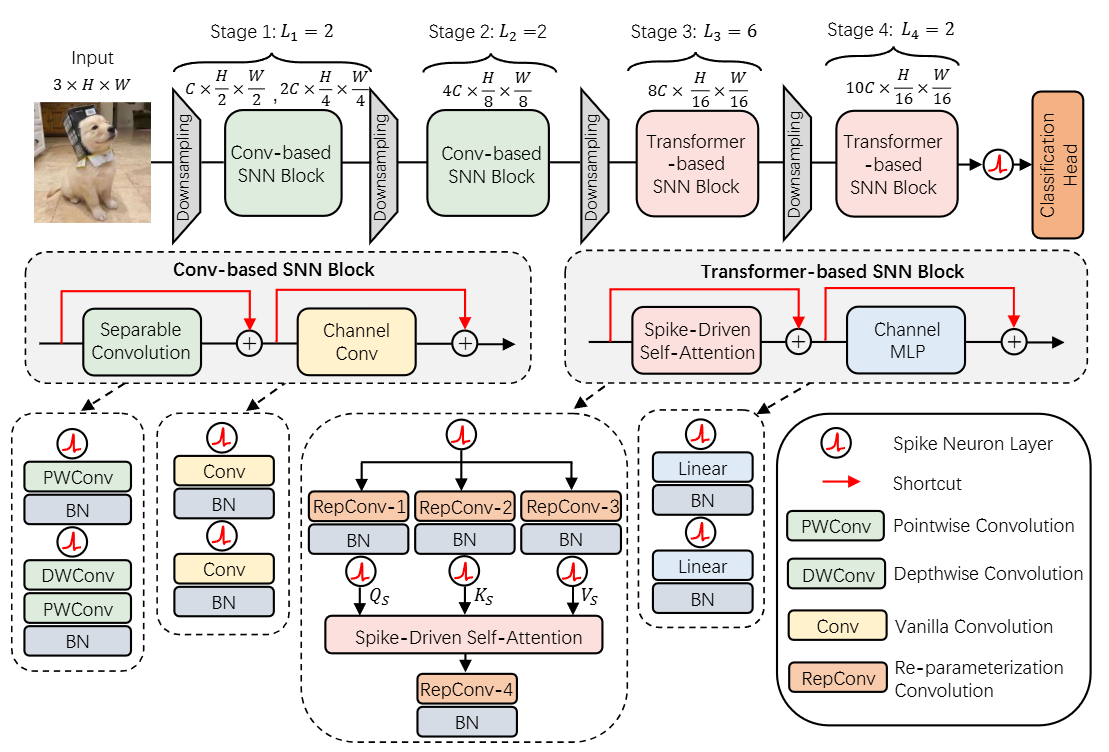
Meta-spikformer는 크게 incoding을 위한 conv-based SNN blok와 연산을 위한 transformer-based SNN block로 나뉜다. 중간중간 conv 기반 downsampling layer를 둠으로써 채널 수를 절반으로 줄여나가는데, 마지막 block에서는 파라미터 수 조절을 위해 채널을 16$C$가 아닌 10$C$로 제한한다. 이 전체 구조는 MetaFormer의 구조와 동일하다.
Key Equations
Conv-Based SNN Block
이 논문에서 쓰인 Block들은 모두 MetaFormer에서 제안한 Tocken mixer + Channel MLP의 구조를 따른다.
conv-based snn block은 separable convolution(Tocken Mixer 역할)과 channel convolution(Channel MLP 역할)으로 나뉜다.
separable convolurion은 point-wise convlution을 통해 채널 수를 확장시킨 뒤, depth-wise convolurion을 사용해 tocken mixer로서의 역할을 한다. 이후 point-wise convolution을 통해 채널 수를 되돌린다.
\[\operatorname{SepConv}(U) = \operatorname{Conv}_{\text{pw2}}(\operatorname{Conv}_{\text{dw}}(\operatorname{SN}(\operatorname{Conv}_{\text{pw1}}(\operatorname{SN}(U)))))\]channel convolution에서는 두 번의 convolution연산을 통해 channel mixing을 달성한다.
\[\operatorname{ChannelConv}(U') = \operatorname{Conv}(\operatorname{SN}(\operatorname{Conv}(\operatorname{SN}(U')))).\]Transformer-Based SNN Block
transformer-based snn block에서는 re-parameterization convolution을 적용한 SDSA-3을 tocken mixer로 사용하고, MLP를 channel mixer로 사용한다.
\[U' = U + \operatorname{RepConv}_4(\operatorname{SDSA}(Q_S, K_S, V_S)),\] \[U'' = U'+\mathrm{ChannelMLP}(U'),\] \[\mathrm{ChannelMLP}(U ′) = \mathrm{SN} (\mathrm{SN} (U ′)W1)W2,\]SDSA-1, 2는 요소별 곱을 사용한다는 강력한 장점이 있지만, 성능 측면에서 SDSA-3이 더 우수했기에 본 논문에서는 SDSA-3을 채택하였다. SDSA-4의 경우는 3과 성능차이가 없었기에 채택하지 않았다.
Results
본 논문의 MetaSpikformer는 다용성(versatility)을 중시한 만큼 다음 네 과제에 대해 테스트를 진행했다.
1. Image Classification
ImageNet-1K는 컴퓨터 비전에서 가장 널리 사용되는 데이터셋이다. 1000 개의 클래스가 있으며, 약 130만개의 훈련 이미지와 5만 개의 검증 이미지로 나뉜다.
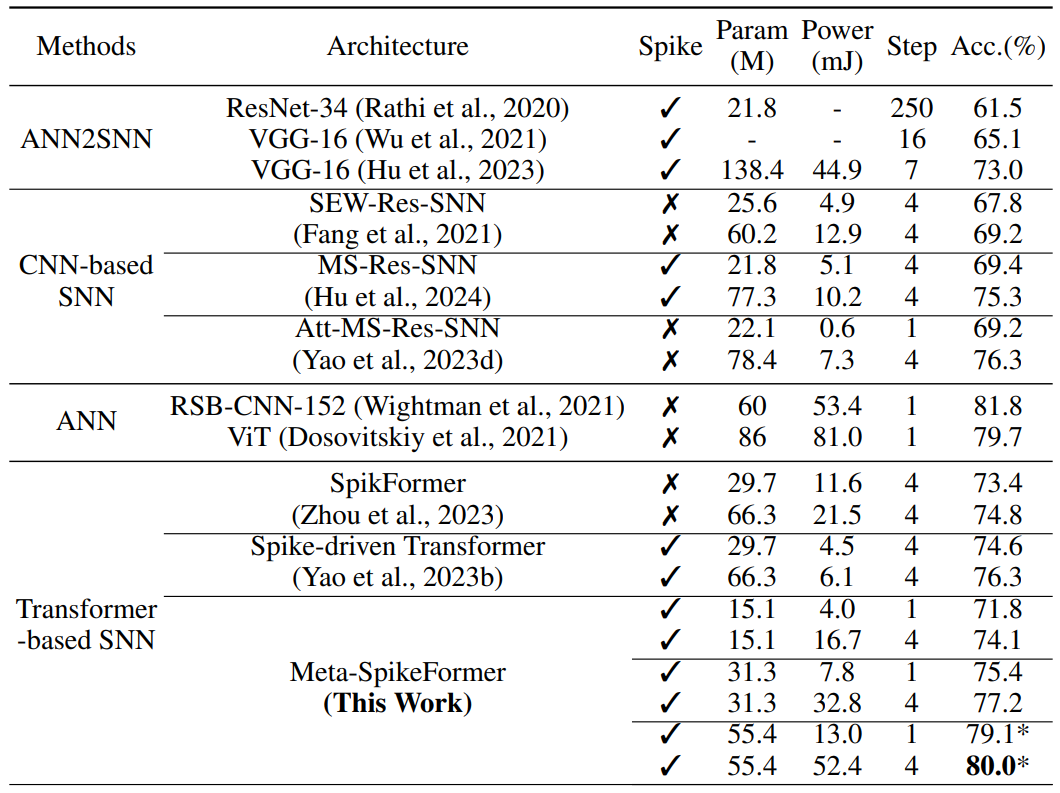
Meta-Spikeformer만 봤을 때 세 칸은 각각 embedding tocken 수($C$)를 32, 48, 64로 다르게 하며 측정한 결과이다. 각 칸에서 위쪽은 모델을 바로 돌린 결과, 아래쪽은 Deit 증류(distillation)를 적용한 결과이다.
저자의 이전 논문인 Spiek-driven Transformer와 Meta-Spikformer를 비교하면 하이퍼파라미터 수가 약 17%가 감소했음에도 정확도는 3.7%p가 증가한 것을 볼 수 있다. 이는 SNN 분야에서 SOTA급 성능이며, 마의 80% 구간을 돌파한 결과이다.
2. Event-Based Action Recognition
event-based vision(neuromorphic vision이라고도 함)은 가장 전형적인 뉴로모픽 컴퓨팅의 응용 시나리오이다. Dynamic Vision Sensors(DVS) 카메라는 시각 정보를 밝기 변화가 있을 때만 spike를 포함한 희소 정보로 인코딩하는 방식으로 촬영한다. 그 결과 SNN은 이 데이터를 저전력 및 저지연이라는 고유한 이점을 살려 처리할 수 있다.
본 연구에서는 HAR-DVS라는 이벤트 기반 인간 활동 인식 데이터셋을 사용한다. 300개의 클래스와 107,646 개의 샘플이 있으며 공간 해상도는 346 × 260이다. 해당 데이터셋은 주소가 있는 스파이크를 다루므로 데이터의 크기가 4T로 매우 크기에 각 샘플을 프레임으로 변환해 새로운 HAR-DVS를 구성한 뒤, T=8로 설정해 직접 훈련 방식으로 데이터를 처리했다.

표에서 볼 수 있듯 Meta-Spikeformer는 ANN과 비슷한 정확도를 달성했으며, Conv-based SNN 베이스라인보다 우수한 것을 알 수 있다.
3. Object Detection
COCO benchmark는 이미지 탐지에 쓰이는 데이터셋으로 11만 8천개의 학습 이미지와 5천 개의 검증 이미지가 있다. SNN에서 활용하기 위해 mmdetdction을 스파이킹 버전으로 변환해서 사용했다.
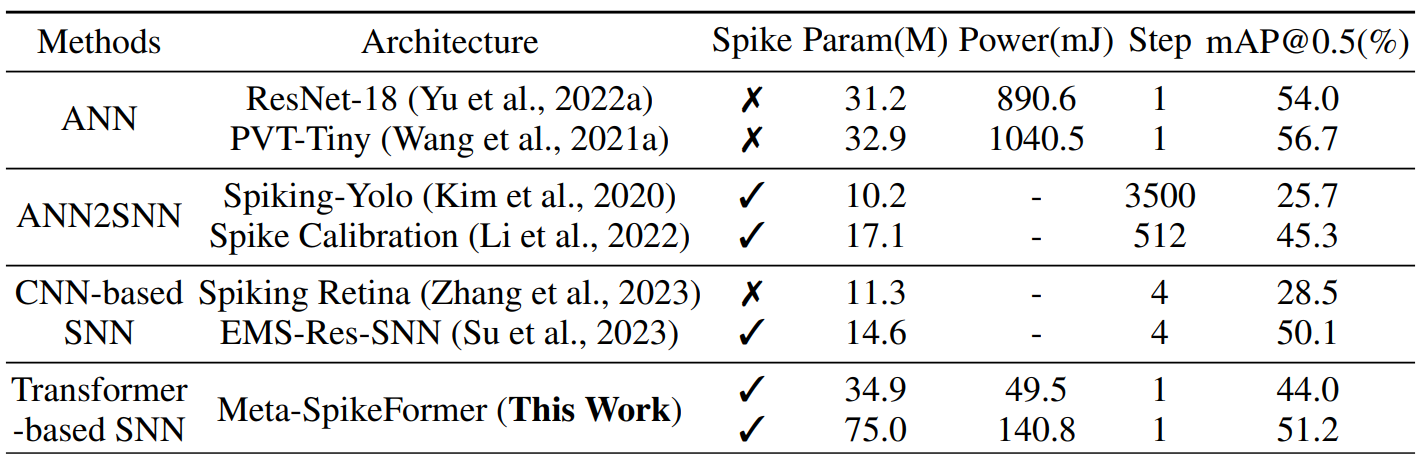
여기선 ImageNet을 통해 pre-train된 Meta-Spikformer를 백본 초기화에 사용하여 Mask R-CNN과 함께 활용했다. 결과를 보면 역시 SNN 분야에서 SOTA를 달성했음을 알 수 있다.
참고로 EMS-Res-SNN은 14.6M 개의 파라미터만으로 본 논문과 유사한 성능을 냈기에, 공정성을 위해 Meta-Spikeformer + YOLO를 사용해 비교하면 다음과 같은 결과가 나온다.

이때도 역시 Meta-Spikformer가 더 나은 성능을 얻었음을 알 수 있다.
4. Semantic Segmentation
ADE20K는 ANNs에서 일반적으로 사용되는 의미론적 분할 벤치마크로, 2만 개의 학습 데이터와 2천 개의 검증 데이터를 포함한 150개의 범주를 다룬다. 아직 ADE20K에서의 처리 결과를 보고한 SNN은 없다.
본 연구에선 mmsegmentation을 스파이킹 버전으로 변환하여 모델 실행에 사용했다. ImageNet을 통해 학습된 결과를 백본 초기화에 활용하고, Semantic FPN을 장착했다. 다른 레이어는 Xavier를 사용해 초기화했다.
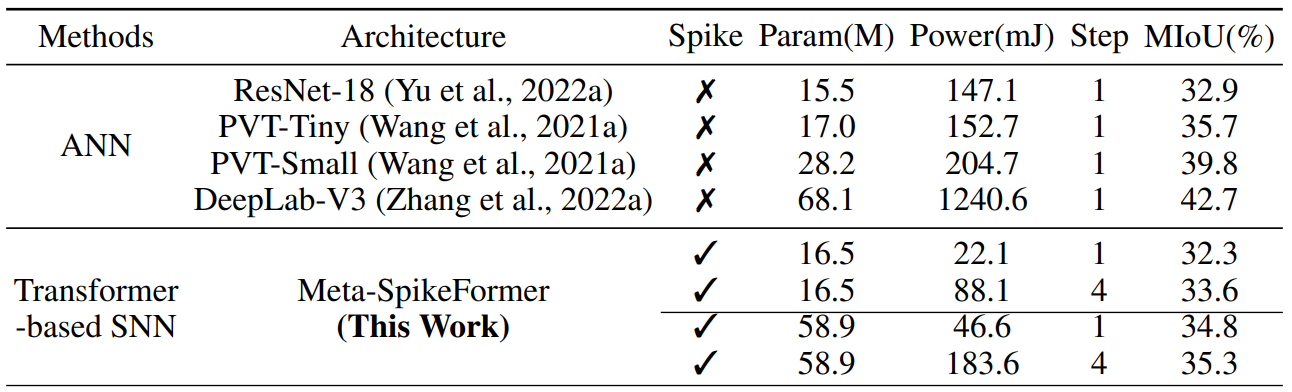
결과를 보면 Meta-SpikFormer가 낮은 전력으로도 ANN과 유사한 성능을 내고 있음을 알 수 있다. 특히 T=1인 경우를 보면 ResNet-18과 PVT-Tiny와 비교했을 때 비슷한 성능과 파라미터를 갖지만 에너지 효율이 매우 좋다.
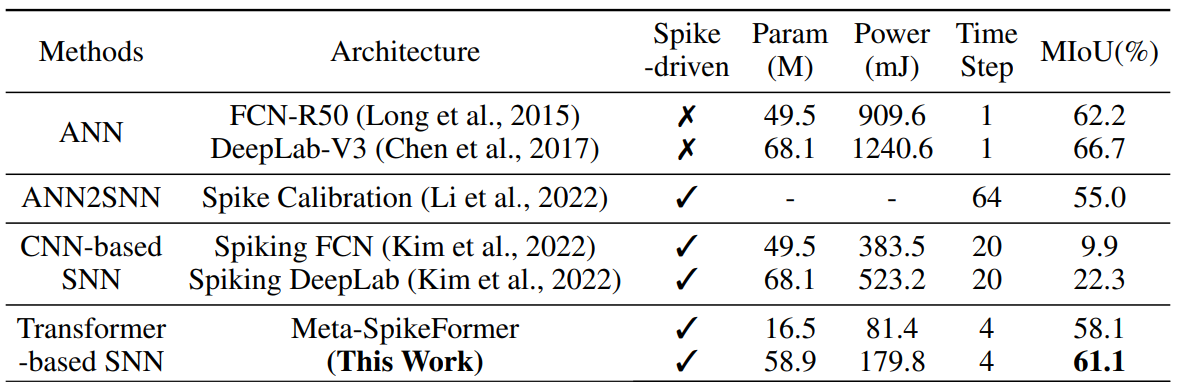
다른 SNN과의 비교를 위해 VOC2012에서도 본 방법을 평가했으며 SOTA 결과를 달성했음을 알 수 있다.
Ablation Studies
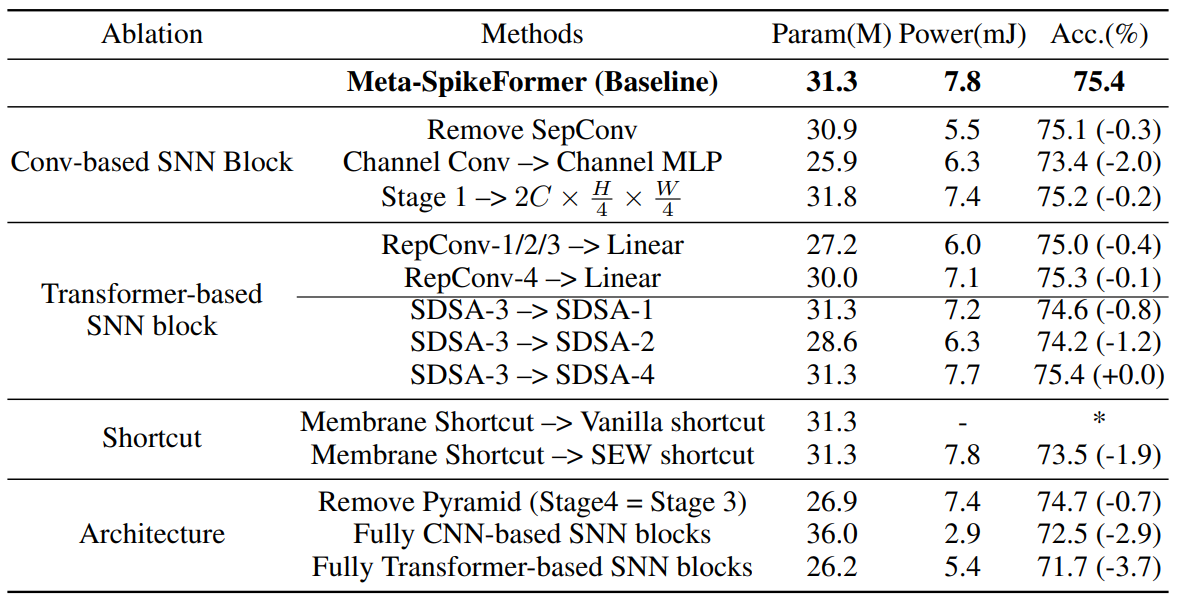
ImageNet-1K에서 $C=48$, $T=1$일 때를 기준으로 하이퍼파라미터를 바꾸어가면서 보면 다음과 같다.
-
Conv-based SNN Block: 해당 블록에선 SpeConv를 Tocken mixer로 사용하는 것이 성능 변화에 큰 영향을 주진 않지만, Channel Conv를 MLP로 변환했을 경우 성능이 크게 감소함을 알 수 있다. 따라서 Conv 기반 SNN 블록의 설계가 중요함을 알 수 있다.
-
Transformer-based SNN Block: SDSA에서 Linear를 RepConv로 교체한 경우, 에너지 비용이 증가하지만 정확도를 늘리고 파라미터 수를 줄일 수 있다. 어떤 SDSA 연산을 사용할지도 정확도에 영향을 주는데 SDSA3을 사용한 경우 가장 높은 계산 복잡도를 가지지만$O(ND^2)$ 성능 또한 가장 좋음을 알 수 있다.
-
Shortcut: MS 방식이 가장 높은 정확도를 보임을 알 수 있으며, shortcut은 전력과 파라미터 등에 거의 영향을 미치지 않는다.
-
Architecture: 네트워크를 완전한 Conv-Base 또는 Transformer-Base로 바꾼 경우 성능이 현저히 감소했다. 다만 전력 또한 현저히 감소했는데 이는 전력 및 정확도 측면에서 다양한 절충안이 있음을 시사한다.
Discussion
How does Meta-SpikFormer inspire future neuromorhpic chip design?
본 논문에서 제시한 Meta-SpikFormer가 차세대 뉴로모픽 칩 설계에 주는 기술적 영감은 다음 세가지로 정리할 수 있다.
- Conv + Vit desgine: MetaFormer에서 채택한 형태가 SNN에도 여전히 유효하다.
- SDSA operation: SDSA 연산은 transformer 기반 SNN의 핵심이며, neuromorphic에 적용 가능하다.
- Meta architecture: Meta-SpikFormer의 구조 안에서 정확도, 파라미터 수, 필요 전력을 고려해 하이퍼파라미터를 조정할 수 있다.
Theoretical Energe Evaluation
이론적 에너지 소비 추정은 간단한 공식으로 이루어질 수 있다. ANN의 경우, FLOPs 수에 MAC 연산에 쓰이는 에너지의 크기를 곱하면 된다.
\[E_{ANN} = \mathrm{FLOPs}\cdot E_{MAC}\]SNN의 경우는 MAC 연산이 AC 연산으로 바뀌며, 여기에 time step과 발화율을 고려해야 하기에 다음 공식을 따른다.
\[E_{SNN} = \mathrm{FLOPs}\cdot E_{AC}\cdot T\cdot R\]이 공식을 따르면 같은 FLOPs를 가질 때 ANN의 경우와 SNN의 경우는 결과값이 매우 다를 수밖에 없다. 단순히 쓰이는 에너지 양만 봐도 MAC 연산은 $E_{MAC}=4.6pj$고, AC 연산은 $E_{AC}=0.9pj$로 5배 이상 차이가 난다. 거기에 발화율이 적을 수록(희소할 수록) 소모되는 에너지가 더 적어진다. 다만 time step까지 고려한다면 이론적 에너지 소비 차이는 줄어들 수 있다.
Insights
Meta- Structure
SNN에 MetaFormer를 접목시켰다는 점이 이 논문의 핵심으로 보인다. MetaFormer에 대해 잘 알지 못해서 레퍼런스 논문을 찾아서 읽어봤는데, 이 논문보다 MetaFormer에 더 인상깊게 보았다. transformer를 배울 때 핵심 메커니즘으로 self-attention을 사용하기 때문에 높은 성능을 낼 수 있었다고 배웠는데, 사실 attention이 아니라도 적절한 tocken mixer를 사용하기만 한다면 높은 성능을 낼 수 있다는 부분에서 기존 패러다임이 바뀌었다.
이 패러다임의 변화는 단순히 MetaFormer의 구조에 그치지 않고, Spikeformer에 시사하는 점이 크다고 생각한다. SpikeFormer 관련 논문을 읽으면서 항상 드는 의문은 attention 매커니즘이 ANN과 근본적으로 차이가 난다는 점이었다. ‘과연 이 구조를 attention이라고 할 수 있을까?’ MetaFormer 논문은 구조가 같으면 가능하다는 답변을 주었고, 이 논문은 그게 SNN에도 적용 가능함을 보여주었다.
Shortcut
본 논문은 SNN의 Shortcut에 대해 논의하면서 어떤 문제점이 발생 가능하고 이걸 어떤 방식으로 해결 가능한지 얘기하면서 Membrane Shortcut을 적용한 근거를 마련했다. 하지만 막 전위를 직접 연결한다는 점에서 생물학적 타당성을 잃어버리는 결정을 해버린 것같아서 아쉽다는 생각이 들었다. 생물학적 타당성을 잃지 않으면서 기울기 소실 문제가 없으려면 어떻게 해야할까 하는 생각이 들었다. 아마 local learning을 적용해 기울기 소실을 고려할 필요가 없어지면 괜찮지 않을까 한다.
SDSA-3
본 논문에서는 성능을 극대화하기 위해 즉, 80%라는 마의 벽을 깨기 위해 행렬곱을 사용하는 SDSA-3을 적용했다. 이는 이전 논문인 Spike-driven transformer에서 에너지 효율을 위해 요소별 곱을 도입한 것과 대조적이다. 이로 인해 시간 복잡도는 $O(ND)$에서 $O(ND^2)$으로 증가했다. 여전히 $N$에 대해선 선형이라고는 하지만, 실제 적용한 모델을 보면 토큰 수보다 채널 개수가 더 많은 것을 알 수 있다. 이는 논문에서 말하는 효율성과 대조되는 결과라고 생각해서 아쉬웠다.
References
-