QKFormer: Hierarchical Spiking Transformer using Q-K Attention
Paper Info
| Field | Content |
|---|---|
| Title | QKFormer: Hierarchical Spiking Transformer using Q-K Attention |
| Authors | Chenlin Zhou et al. |
| Venue | NeurIPS 2024 |
| Year | 2024 |
| Link | arxiv |
Summary
QK-Attention을 Spikeformer에 적용한 논문
Problem Statement
Space complexity of spikformer
SNN의 성능을 극대화하기 위해선 Transformer 아키택처가 필수적이다. 그러나 공간 복잡도 측면에서 두 가지 어려움이 존재한다.
- Spiking Self Attention(SSA)에서의 계산 복잡도는 토큰 수에 대해서 제곱으로 증가한다.
- SSN은 시간 영역에 걸처 데이터를 처리하기에 높은 수준의 계산 및 메모리 리소스가 요구된다.
이러한 한계점을 보완하기 위해 본 논문에서는 Q-K attention, hierarchical architecture, novel patch embedding with deformed shortcut을 적용한 QKFormer를 제안한다. 이 설계는 에너지 소비와 공간 요구 사항을 낮추며 모델 성능도 준수하다.
Key Idea
Q-K Attention
VSA, SSA
Vanilla Self Attention
Transformer의 기존 셀프 어텐션은 학습 가능한 선형 행렬과 입력 $X$에 의해 계산되는 $Q$, $K$, $V$의 행렬곱 즉 부동 소수점 연산으로 계산된다.
\[Q_F, K_F, V_F = X(W_Q, W_K, W_V) \\ VSA(Q_F, K_F, V_F) = \mathrm{Softmax}\left (Q_FK_F^T\over\sqrt{d_k}\right)V_F\]이때 $F$는 부동 소수점 형태를 나타내는데, 이처럼 부동 소수점을 사용하는 행렬 곱셈, 지수 계산과 나눗셈을 포함하는 소프트멕스 연산 등은 모두 SNN의 속성과 일치하지 않는다.
Spiking Self Attention
반면 SSA는 SNN에 맞게 VSA를 변형한 형태이다.
\[I = \text{SN}_I(\text{BN}_I(X(W_I))),\quad I\in \{Q,K,V\} \\ \text{SSA}'(Q, K, V) = \text{SN}(QK^T*s)V\]여기서 $Q,K,V\in\mathbb{R}^{{T\times N\times D}}$이고 $Q$, $K$, $V$는 학습 가능한 선형 레이어를 통해 계산된 스파이크 형태의 텐서이다. $s$는 스케일링 펙터로 VAS에서의 $1/\sqrt{d}$를 대신한다. SSA는 소프트맥스 연산과 부동소수점 행렬 곱셈을 피해서 SNN의 속성을 만족시킨다.
Q-K Attention
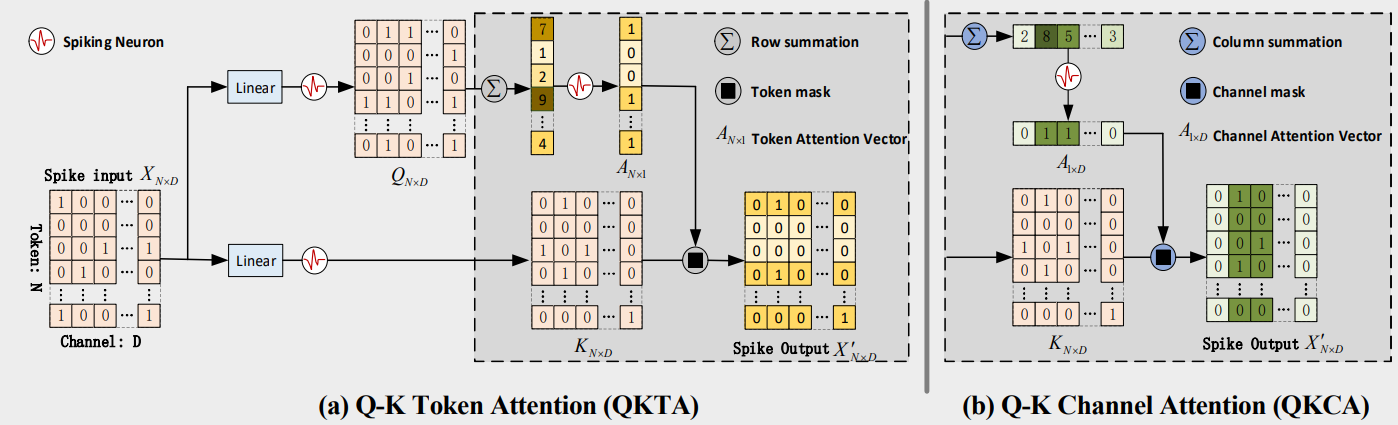
VSA와 SSA는 $Q$, $K$, $V$라는 세 가지 핵심 구성 요소를 모두 연산에 사용하며, 이로 인해 $O(N^2D)$ 혹은 $O(ND^2)$의 계산 복잡도를 가진다. 반면 Q-K attention은 선형 복잡도를 가지며, $Q$와 $K$만을 사용한다.
\[Q=\text{SN}_Q(\text{BN}(XW_Q)),\quad K=\text{SN}_K(\text{BN}(XW_K))\]이때 $X$는 입력 스파이킹 맵이다. Q-K Attention은 Tocken Q-K Attention(QKTA)과 Channel Attention(QKCA)으로 나눌 수 있다.
Q-K Token Attention
수학적 설명을 위해 T=1, 단일 헤드 attention을 가정하면 QKTA는 다음과 같이 공식화될 수 있다.
\[{A}_t = \operatorname{SN}\left(\sum_{i=0}^{D} {Q}_{i,j}\right), \quad {X}' = {A}_t \otimes {K},\]여기서 $A_t$는 다양한 토큰의 중요도를 모델링하는 N*1의 토큰 attention 벡터이다. $\otimes$는 스파이크 텐서 간의 요소별 곱(hadamard product)으로 특정 값만 통과시키는 마스크 연산과 동일하다.
Q-K Channel Attention
QKCA의 계산과정은 QKTA와 유사하며, 다음과 같이 공식화될 수 있다.
\[{A}_c = \operatorname{SN}\left(\sum_{j=0}^{N} {Q}_{i,j}\right), \quad {X}' = {A}_c \otimes {K},\]이때 $A_c$는 다양한 채널의 중요도를 모델링하는 1*D의 채널 attention 벡터이다. 역시 $\otimes$는 마스크 연산과 동일한 역할을 수행한다.
\[{X}'' = \operatorname{SN}(\operatorname{BN}(\operatorname{Linear}({X}'))).\]위 식에서 보다시피 $X’$은 최종적으로 선형 계층을 지나 $ {X}’’ $으로 변환된다. 추가적으로 multi-head A-K Attention에서는 채널 차원이 $D/h$이며, time step $T$는 스파이킹 뉴런 계층에 대한 독립적인 차원이다. 본 연구에선 스파이킹 뉴런으로 LIF 모델을 사용하며, QKTA을 활용한다.
Structural efficiency & numerical stability
No scaling factor
VSA에서 $Q$와 $K$를 평균 0, 분산 1을 따르는 독립적인 확률 변수라고 했을 때 둘의 행렬곱의 각 요소는 평균 0, 분산 $d$를 가진다. 이 경우 softmax 함수를 통과하면서 기울기 소실 문제로 이어질 수 있으므로 정규화를 위해 $1/\sqrt{d}$를 곱해주게 된다. SNN의 경우 softmax 함수를 사용하지는 않지만, 분산이 커지면 성능에 영향을 주거나 수렴이 잘 되지 않기에 스케일링 펙터 $s$를 곱해주어서 문제를 해결한다. 반면 Q-K attention의 분산은 SSA에 비해 훨씬 작다. Q-K attention의 최대 이론적 분산은 SSA의 약 1/200 정도에 불과하기 때문이다. (이유에 대한 이해 및 내용 보충)
Linear computational conplixity of Q-K Attention

표에서 볼 수 있듯이 Q-K attention의 시간 및 공간 복잡도는 구현 방식에 따라 달라진다. 브로드캐스트 방식으로 요소별 곱 $\otimes$을 활용할 경우 시간 복잡도는 최대 $O(ND)$에 달할 수 있다. 이때 마스크 연산을 적용하게 되면 시간 복잡도는 최대 $O(D)$ 혹은 $O(N)$까지 떨어질 수 있다. 이 경우 공간복잡도는 $A_t$ 혹은 $A_c$ 벡터를 저장할 공간인 1*D 또는 N*1 정도만 요구된다.
Hight Energe Efficiency
Q-K attention은 스파이크 기반 attention 모듈이므로 선형 곱셈은 희소 덧셈으로 변환된다. 마스크 연산은 뉴로모픽 칩에서는 주소 지정 알고리즘 혹은 AND 논리 연산을 통해 전력 소비를 줄일 수 있다. 같은 스파이크 기반 attention인 SSA와 비교했을 때 Q-K attention은 다음과 같은 이유로 훨씬 더 에너지 효율적이다.
- $V$가 없이 두 개읜 구성 요소만 채택하므로 시냅스 연산량이 적음
- 시간, 공간 복잡도가 $O(N)$ 혹은 $O(D)$의 선형 복잡도로 행렬 연산이 적음
- SSA의 스케일 연산이 없기에 전력 소비를 아낌
Hierarchical Architecture
기존 SSA를 사용한 spikformer의 경우 토큰 또는 채널에 대해 제곱으로 복잡도가 증가하므로 계층적 구조를 적용했을 때 메모리 폭발이 쉽게 발생하는 문제가 있었다. Q-K attention을 기반으로 한 QKFormer의 경우, 토큰 또는 채널에 대해 선형 계산 복잡도를 가지기에 이런 문제가 없으며, 이로 인해 계층적 특징 맵을 구성할 수 있다.
이에 QKFormer에선 블록을 지나면서 토큰의 수는 줄어들고, 채널의 수는 늘어나는 계층적 구조를 적용했다. 깊은 층으로 갈수록 더 다양한 표현이 가능해져 성능이 증가했다.
Spiking Patch Embedding with Deformed Shortcut(SPEDS)
SNN에서 잔차 연결은 항등 사상(identity mapping)을 구현할 수 있으며, 이는 정보 손실을 줄여 네트워크의 깊어도 잘 작동할 수 있도록 한다. 기존 Spikformer에선 잔차 연결을 사용해 항등 사상을 달성했지만, 다운샘플링 블록을 가로지르는 patch embedding에서는 사용하지 않았다. QKFormer에서는 잔차 연결에 경랑 선형 투영 $W_d$를 수행해 채널과 토큰 수를 일치시며 다운샘플링 블록을 가로지르는 항등 사상을 실현할 수 있다.
본 논문에서 논의한 잔차 연결 방식은 두 가지 유형이다. 하나는 활성화 후 덧셈 방식이고, 다른 하나는 사전 활성화 방식이다.
Activation Befoer Addition
활성화 후 덧셈 방식(ABA)은 스파이킹 레이어를 통과한 뒤 이를 잔차 연결으로 더하는 방식이다.
\[Y = F(X, \{W_i\})+\text{SN}(W_dX)\]여기서 사용된 선형 투영 $W_d$는 1$\times$1커널과 stride > 1을 갖는 경량 Conv 레이어로, patch embedding의 채널 및 토큰 수를 충족시킨다. 본 연구서는 함수 $F$를 다음으로 설정했으며, 다른 변형도 가능하다.
- Conv2D - BN - MaxPooling - SN - Conv2D - BN - SN 또는
- Conv2D - BN - SN Conv2D - BN - MaxPooling - SN
Pre-Activation
반면 사전 활성화 방식(PA)은 다음과 같이 공식으로 나타낼 수 있다.
\[Y = \text{SN}(G(X, \{W_j\})+W_dX)\]여기서 함수 $G$는 다음으로 설정했다.
- Conv2D - BN - MaxPooling - SN - Conv2D - BN 또는
- Conv2D - BN - SN - Conv2D - BN - MaxPooling
논문에서는 활성화 후 덧셈 방식을 기준점으로 잡아서 실험을 진행하였다.
Methods
Overall Architecture
위에서 언급한 QK-Attention, Hierarchical Architecture, SPEDS 등을 적용한 최종적인 구조는 다음과 같이 시각화할 수 있다.
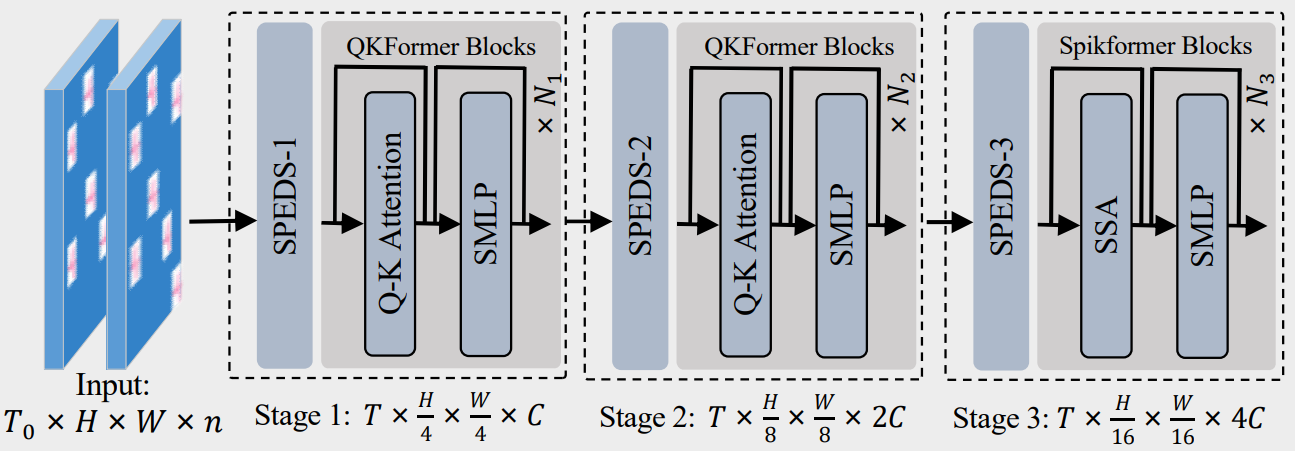
그림에서 보이는 입력 형태인 $T_0\times H\times W\times n$은 이미지 데이터셋, 뉴로모픽 데이터셋을 일반화한 것이다. 입력 시 패치 크기를 4$\times$4로 하기에 SPEDS-1을 거친 뒤에는 $T_0\times {H\over 4}\times {W\over 4}\times C$가 되고 이후엔 다운샘플링을 할 때마다 토큰은 절반으로, 채널은 두 배로 증가한다. 모든 블록을 통과한 뒤에는 FC layer가 분류기 역할을 한다.
특징적인 것은 마지막 블록에서 Q-K Attention이 아니라 SSA가 사용된다는 점이다. 계층적 구조를 사용하기 때문에 후반 블록은 채널 수가 많고 토큰 수가 적은데 이때 QKTA를 사용하게 되면 이 풍부한 채널 간의 상호작용을 파악하기 힘들다. 이에 후반 블록은 SSA나 QKCA를 사용하는 것이 성능에 유리하며, 본 논문에선 기준값으로 SSA를 사용했다.
Key Equations
QK-Attention based transformer block
QKFormer의 블록은 기존 transformer의 블록과 유사한 형태로, Q-K Attention 모듈과 Spiking MLP(SMLP)로 구성되며, 다음과 같이 공식화할 수 있다.
\[X_l'=QKTA(X_{l-1})+X_{l-1} \\ X_l=SMLP(X_l')+X_l'\]SPEDS layer in architecture
SPEDS는 앞서 언급했듯이 잔차 연결에 경랑 선형 투영 $W_d$를 수행해 항등 사상을 실현하기 위해 사용된다. 본 논문에서는 처음 단계에서는 spike encoder까지 포함한 SPEDS를 사용했으며, 2, 3단계에서는 encoder를 제외한 구조를 사용했다.
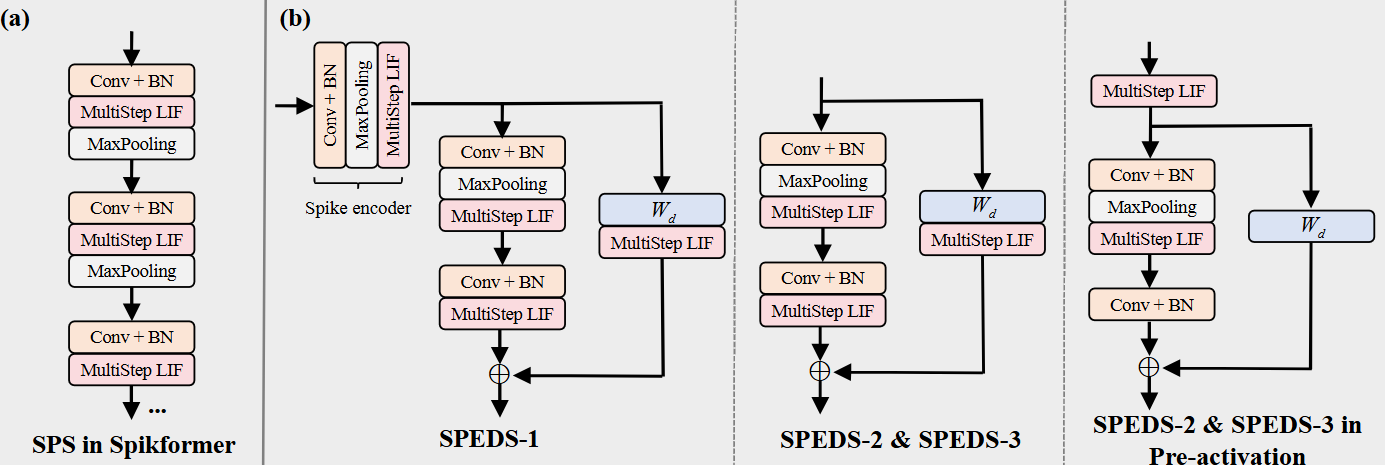
본 논문의 모델에서는 기본적으로 activation before addition 방식을 사용했으며, 이 부분을 pre-activation으로 교체할 수도 있다고 명시한다.
Results
ImageNet-1k Classification
논문에서 설명한 ImageNet 주요 실험 설정은 다음과 같다.
- potimizer: AdamW
- learning rate: BatchSize/256 * 6e-4
- batch size: 512
- epochs: 200
- data augmentation: RandAugment, random erasing, stochastic depth
- number of blocks: 1, 2, 7
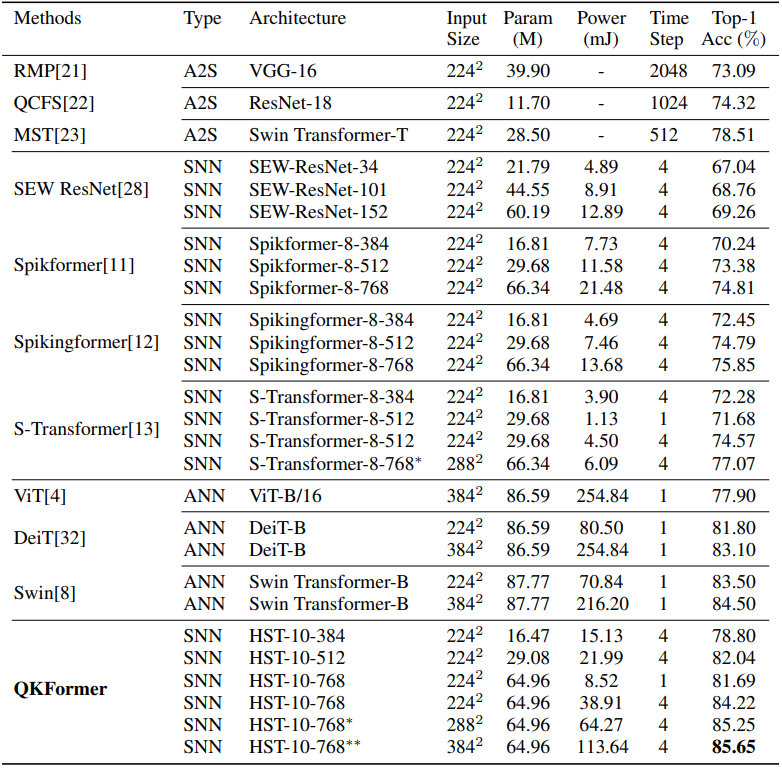
결과에서 볼 수 있둣 QKFormer는 상당히 우수한 성능을 보여주며, 가장 성능 좋은 모델은 85.65%의 top-1 정확도와 97.74%의 top-5 정확도를 달성했다. 같은 Spikformer 모델에서 비슷한 파라미터 대비 가장 우수한 성능을 보이며, 더 적은 timestep을 사용하더라도 좋은 성능을 보인다. ANN과 비교하더라도 현재 잘 알려진 모델인 Swin에 비해 높은 에너지 효율성을 유지하면서도 뛰어난 성능을 보였다.
CIFAR and Neuromorphic data
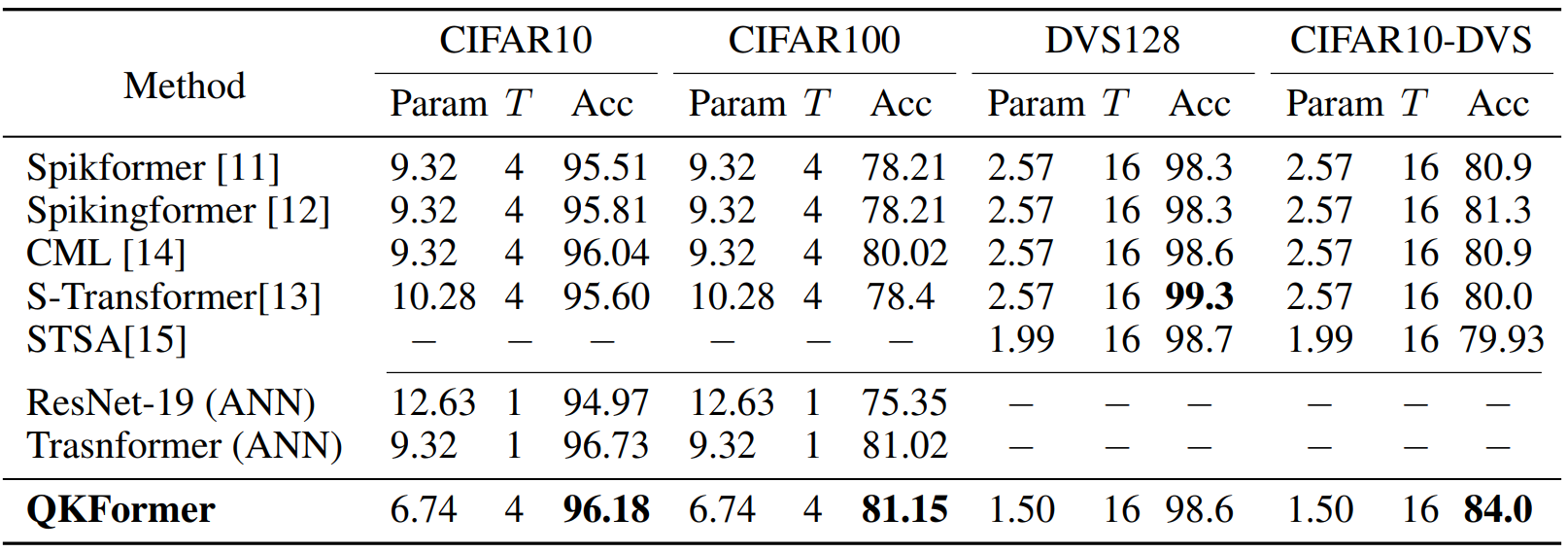
본 실험 CIFAR 데이터는 이전 연구인 Spikformer를 따라 4개의 블록을 사용해서 400 에폭 동안 64의 배치 크기로 학습시켰다. 블록은 {1, 1, 2}로 분산되었으며, 계층적 구조 덕분에 파라미터의 개수는 6.74M으로 다른 모델 대비 적게 유지했다. 표에서 볼 수 있듯 QKFormer는 기존 spikformer보다 2.58M만큼의 파라미터를 줄이면서 0.67%의 성능 향상을 보였다.
뉴로모픽 데이터의 경우에는 3개의 스테이지에 {0, 1, 1}개의 블록을 가진 1.50M개의 파라미터를 가진 미니 QKFormer 모델을 사용했다. 표에서 볼 수 있듯, 기존 모델에 비해 파라미터의 수는 줄이면서 성능은 비슷하거나 더 나은 것을 알 수 있다.
Analyses on Q-K Attention
Attention visualization
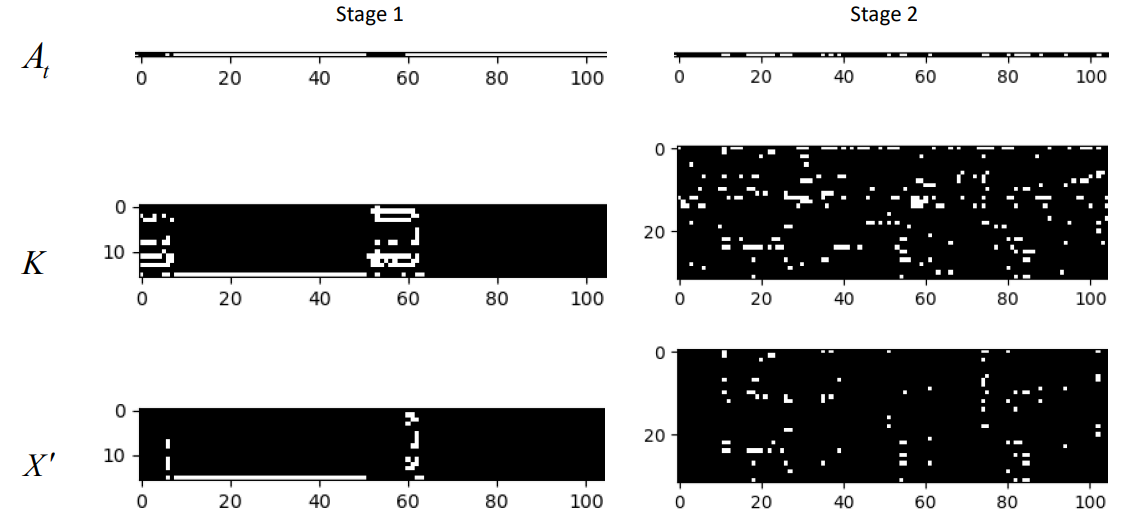
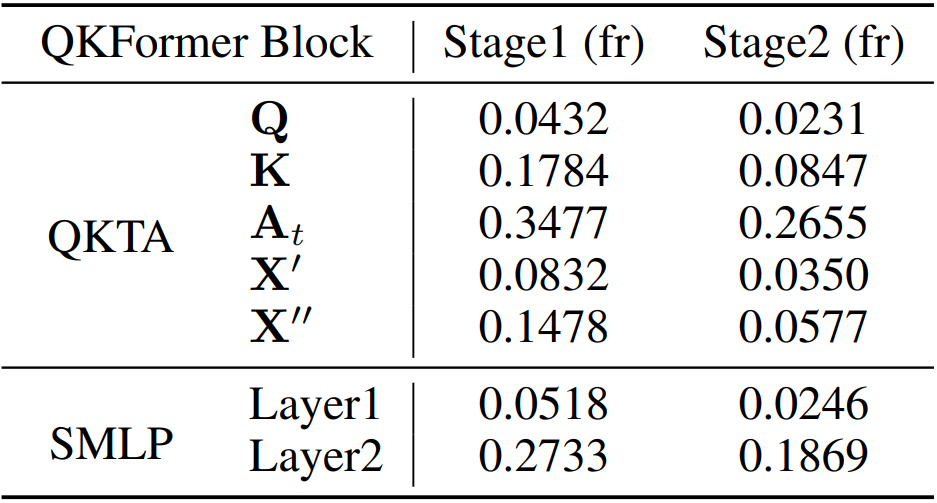
ImageNet-1K에 쓰인 Q-K attention을 시각화하면 위 그림과 같다. (a)에서 $A_t$는 $N\times 1$ tocken attention 벡터이며, $X’$는 행렬 $K$와 벡터 $A_t$ 간의 어텐션 출력이다. 이 시각화 결과는 Q-K attention이 스파이크의 높은 희소성을 유도할 수 있음을 보여준다. 표를 보면 스파이크 형태인 $X’$는 $A_t$와 $K$ 사이의 마스킹 연산으로 얻어지는데 연산을 통해 희소해짐을 알 수 있다.
Memory consumption
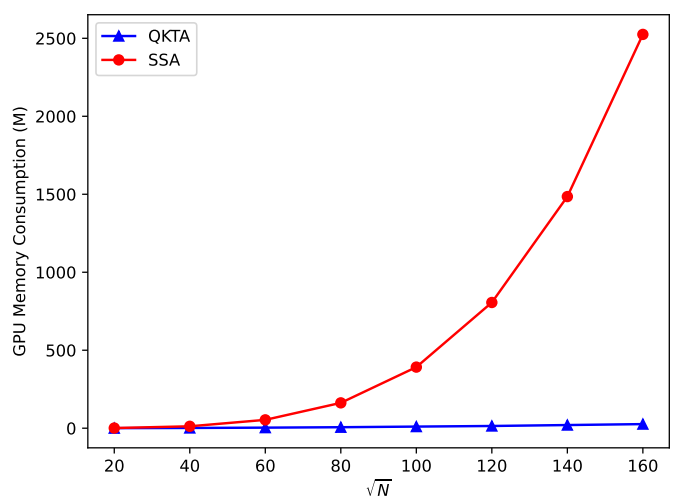
실험에서는 다양한 토큰 수에 대해 QKTA와 SSA 간의 메모리 소비를 비교하고 있다. QKTA의 복잡도는 토큰 수에 선형적으로 비례하며, SSA는 토큰 수가 증가함에 따라 QKTA보다 훨씬 더 많은 GPU 메모리를 소비하는 것을 알 수 있다. 단순히 $\sqrt{n}$이 50일 때 SSA는 QKTA보다 10배 많은 GPU 메모리를 소비한다.
The variance and expectation
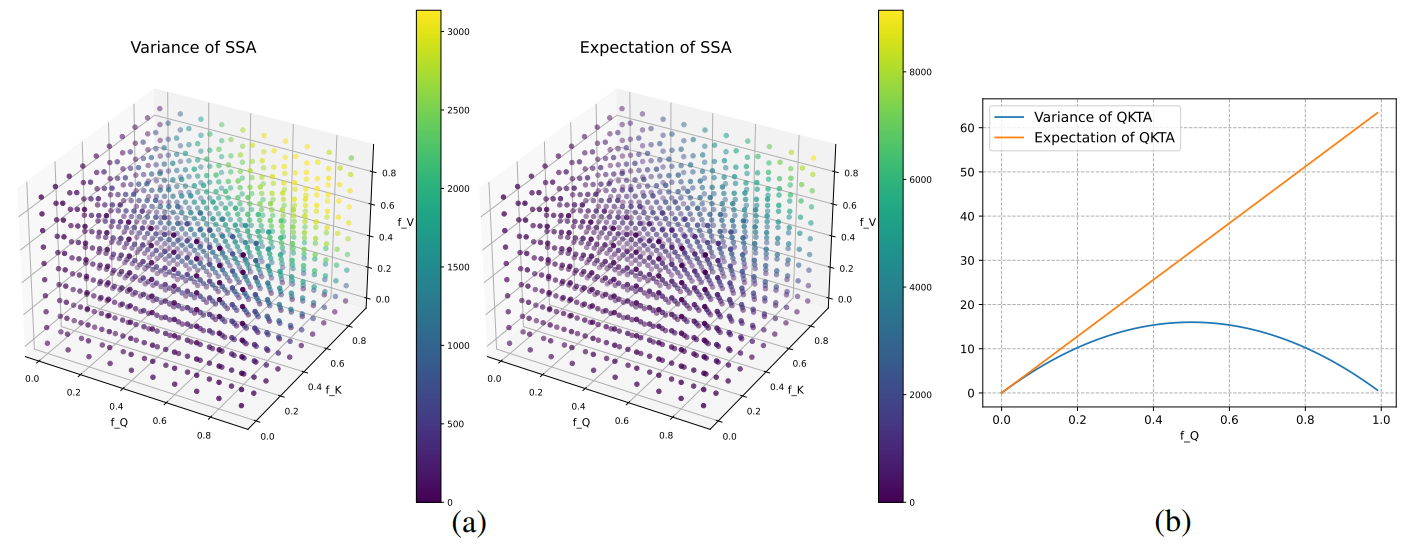
위 그림은 N은 196, d는 64로 설정하여 QKTA와 SSA의 분산 및 기댓값을 시각화한 결과이다. 전반적으로 QKTA에 비해 SSA가 훨씬 큰 분산과 기댓값을 갖는 것을 알 수 있다. 단적으로, QKTA의 최대 이론적 분산은 16인데 반해 SSA의 경우 3000을 초과한다. 이는 전력 소비를 줄일 수 있는 주된 근거가 된다.
Ablation Study
Ablation studies of SPEDS module
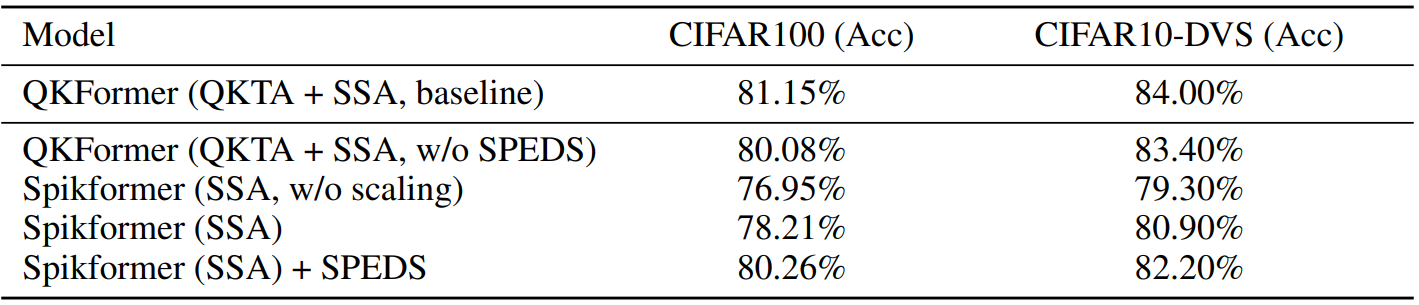
본 실험과 baseline Spikformer에서 SPEDS를 적용한 결과 정적 및 뉴로 데이터셋 모두에서 성능이 향상됨을 알 수 있다.
Ablation studies of Q-K Attention
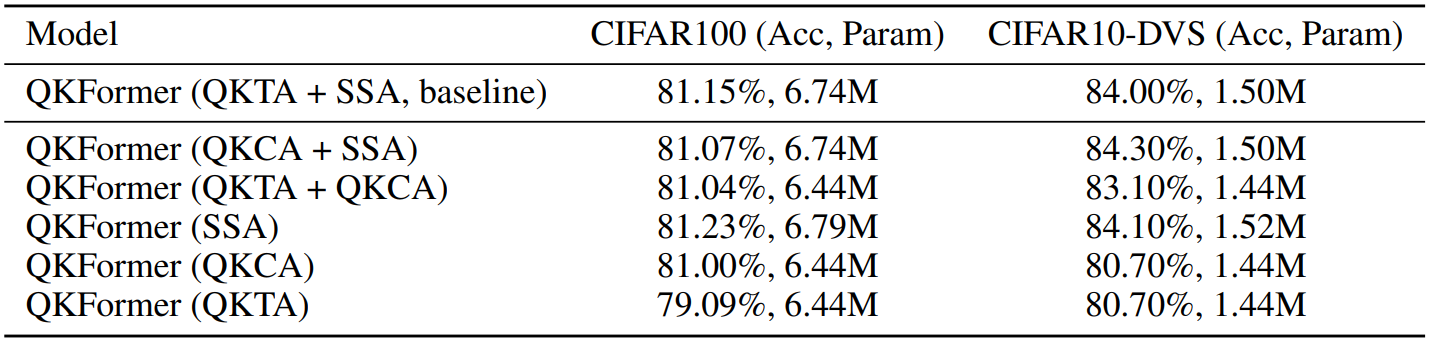
QKTA, QKCA등 여러 attention 혼합과 단일 attention을 사용한 결과를 나타내었다. 단일 SSA를 사용한 결과가 가장 성능이 좋았지만, 계산 효율성과 성능을 모두 고려한다면 QKFormer는 단일 SSA과 유사한 성능을 달성하면서도 더 적은 파라미터와 훨씬 적은 메모리 리소스를 요구한다.
Ablation studies of Residual Connection, Spiking Neuron, Time Step

잔차 연결을 Pre-Activation(PA)로 대체하면 성능이 약간 향상되며, Spiking neuron을 IF(integrate and fire) 및 PLIF(parametric leaky integrate and fire) 방식으로 대체한 경우는 약간의 성능 저하가 발생한다. Time Step의 변화율도 표 하단에서 확인 가능하다.
Discussion
본 논문은 토큰 또는 채널에 대해 선형 복잡도를 가지는 Q-K Attention을 설계했으며, SPEDS를 통해 정보 전송 및 통합을 향상시켰고, 계층적 구조를 반영하여 QKFormer를 개발했다. 실험 결과, 모델은 정적 및 뉴로모픽 데이터셋 모두에서 SOTA 성능을 달성했다.
다만 보델은 이미지/DSV의 분류 작업에 제한된다. 이에 본 논문의 저자는 더 많은 종류의 작업으로 연구를 확장하며, 더 적은 time step을 갖는 효율적이고 고성능인 네트워크 구조를 탐색해나갈 것이라고 한다.
Insights
1 - 2 - 7 blocks?
논문에선 imagenet의 데이터를 분류할 때 QKTA를 쓰는 stage인 stage1과 stage2를 각각 1개, 2개의 블록으로 제한했다. 이는 논문에서 제안한 ‘혁신적인 attention 방식인’ QKTA를 전체 10개 블록 중 단 3번, 그것도 초반에만 사용하고 이후 실제 분석이 이루어질 것이라고 예상되는 stage3에서 기존의 spiking self attention을 사용함을 의미한다. 물론 초반에 Tocken의 수가 feature의 수에 비해 상당히 많음(stage1 기준 12544 vs 768)을 고려했을 때 초반 연산 부담을 많이 줄여준 것은 사실이다. 그러나 abilation studies에서 알 수 있듯이 SPEDS나 계층적 구조가 성능에 더 영향을 준 것으로 보인다. 단일 QKTA만 사용했을 때의 성능이 많이 낮아진 것을 보면 이를 더 실감할 수 있다.
그래서 attention을 어떤 것을 쓸지도 중요하지만, 결국 어떤 구조로 설계를 해야할지, 그리고 각 부분이 어떻게 유기적으로 연결되는지가 더 중요하지 않을까 하는 생각이 들었다. 특히 meta-former에 관한 논문을 접한 뒤로 attention 연산은 tocken mixer 연산이라는 생각이 줄곧 들었는데 본 논문을 읽으면서 그 생각이 더 강화된 것같다. 앞으로 연구를 한다면, attention의 의미와 기능, 그리고 어떤 것이 효율적인지에 대해 깊이 생각을 해봐야겠다.
References
-